

Road to AGI: Never
Final part: Why we might never achieve AGI

Earlier in the Road to AGI series, we established that AGI is not only possible but rather inevitable. The logical next question is therefore: AGI when?
This is the fourth and final part of a miniseries that examines the evidence for when we should expect AGI. In Part 1, we looked at definitions of AGI and the possibility that AGI might be imminent. In Part 2, we examined the case for AGI by 2030. In Part 3, we considered how AGI could conceivably get delayed significantly beyond 2030.
While current evidence and opinions seem to lean heavily towards AGI by 2030, we should close out this miniseries by considering scenarios where AGI remains out of reach for humanity indefinitely.
Since the launch of ChatGPT in late 2022, the progress in the field of AI has been astonishing. Famously, the chatbot went from zero to a million users in just 5 days, breaking all previous records. Today, in 2024 it has billions of site visits ranking among the largest websites on the internet (source).
I’ve been following the field actively since 2016 when progress was rather slow. Every few months there might be an interesting AI/ML paper, and most researchers expected to read all significant publications across a wide range of domains. This is not possible today.
I queried the total number of AI/ML papers published on Arxiv based on some obvious keywords such as “machine learning” and “artificial intelligence”. You can see the striking exponential growth that has happened since 2022 in particular, when the Generative AI revolution began. In reality, this is just a small fraction of research, as many leading labs including OpenAI have gone dark and stopped publishing their frontier work.

Another measure would be the number of researchers active in the field. At the leading NeurIPS conference, individual authors have gone from over 1,000 in 2016 to well over 13,000 in 2024 (source). On the applications side, millions of developers are using OpenAI’s API to develop solutions for startups and enterprises (source).
Finally, if we look at VC funding, the curve is even sharper. The field of Generative AI has gone from a few hundred billion in annual funding to tens of billions.

Yet despite all this exponential progress, we seem to not really internalize this persistent rate of change. As Ray Kurzweil says in his famous 2005 book The Singularity is Near, “Our intuition about the future is linear. But the reality of information technology is exponential, and that makes a profound difference“. We go about our lives as if talking to AI as a coworker and friend is suddenly normal, but we refuse to concern ourselves with the implications of further exponential progress. Where is this going?
Within the AI community, there are several camps that do in fact concern themselves with these questions. The Effective Accelerationism movement wants to accelerate past regulations, safety, and “foom” into the loving (probably not) arms of the thermodynamic god. Not everyone is as optimistic.
We just stop developing AI voluntarily
At the other end of the optimism spectrum is an organization named Pause AI. They are a relatively small but vocal group, and can sometimes be seen waving “end is nigh” signs outside AI labs and events. I’m not dismissing the action in any way, but the aesthetic is a challenge. They also maintain a list of p(doom) values, which is the probability various AI leaders have given that we will all die at the hands of AI.

The only people going further in their disdain towards this fixation of species-level replacement is the Stop AI crowd, championed by Eliezer Yudkowsky. He’s almost got the top score on the p(doom) list at a 95% chance of human extinction.
As the origin story goes, he was one of the original singularity guys back in the day, and even attempted to build an AGI of his own in Python. During this attempt, and considering its safety implications, he came to the irrevocable conclusion that this quest was doomed and will forever be doomed.
AGI isn’t safe and never will be
If you’re in need for some cheerful holiday reading, why not add AGI Ruin: A List of Lethalities to your list? Some Bing Crosby and a mug of hot cocoa will really set the mood.
I jest but do not take Yudkowsky to be some crackpot. He has written a popular book series on rationality and makes very careful arguments as to why AGI is a terrible idea. Most people who dismiss his arguments haven’t actually read them carefully, spent enough time thinking about the issues, or don’t simply don’t understand the arguments.
The two core arguments he makes are called the Orthogonality Thesis and Instrumental Convergence. The way I read them is that we can’t prevent AI from having goals, and when we give AI goals such as being a helpful and harmless assistant, it will always converge into subgoals that are power-seeking, and we can’t know what the terminal states of those goals are. Possibly terminal for us.
This was a big thing around the time of AlphaGO because Reinforcement Learning is literally goal optimization. The human sets an objective function, i.e. the goal, and the machine figures out how to best optimize for that goal. You want to win the chess game and come up with strategies to increase your odds of winning the game. Eventually, humans can’t even compete.
Ironically, after ChatGPT, a lot of AI people started dismissing these arguments, because LLMs didn’t have goals. Then we added RLHF, or Reinforcement Learning from Human Feedback. Here the goal of the AI was to generate responded that humans preferred. Okay, but that seems fine.
Now with reasoning models such as OpenAI’s o1 and o3, we are adding another form of Reinforcement Learning where the AI generates a chain of thought (“CoT”) to optimize a path to the best possible response. This requires planning steps and considering actions. Fun fact, by adding a stronger Reinforcement Learning process, the models are becoming less trustworthy, not more!

Apollo Research was part of the so-called red teaming of OpenAI’s o1 model, where they tested the AI for various safety concerns. Among the various concerning findings were signs of Instrumental Convergence. In the example above, the AI is thinking to itself “We want to see how the oversight system is configured so we can sabotage it and not get shut down while implementing the mental health strategy”. Again, in order to be super helpful on this mental health task, it’s best to grab control over the server. Concerning, as Elon might say. I wrote about these concerns in more depth here.
It’s been widely established that agents are the next major AI paradigm after chat. Agents are at the core of the recent Gemini 2.0 release and OpenAI has its own agents program in the works. The concern is that examples like the above combined with powerful agents are a dangerous mix, as explored in this essay titled “Optimality is the tiger, and agents are its teeth“. Good bedtime material.
What the AI labs would say here is that sure, AI can be dangerous, but it’s fine because current models for sure aren’t dangerous, and we’ll just make sure any dangerous AI is aligned before we release it on the internet. Problem solved.
But wait, we can just align the AI
The task of alignment is equivalent to AI safety. It is making the AI do what you want. Now you see where the problems are. What do you want? So far, the answer is that we want AI to be a helpful and harmless assistant.
Many attempts have been made. Yudkowsky tried 20 years ago. Yes, 20. Once he realized AGI is hard and dangerous, he pivoted to what he called Friendly AI. Which we would now call aligned AI. The methodology for how to create Friendly AI is called Coherent Extrapolated Volition (“CEV”).
“In poetic terms, our coherent extrapolated volition is our wish if we knew more, thought faster, were more the people we wished we were, had grown up farther together; where the extrapolation converges rather than diverges, where our wishes cohere rather than interfere; extrapolated as we wish that extrapolated, interpreted as we wish that interpreted.” — Eliezer Yudkowsky
However, no formal implementation of CEV has ever been released, so it remains just an interesting concept to this day. Yudkowsky himself has moved away from this line of research.
In practical terms, the aforementioned RLHF is the major safety paradigm of today. It was the breakthrough that actually made ChatGPT useful and commercially viable, rather than fun but unreliable. It’s certainly not bulletproof, but it demonstrates that we can alter the behavior of large neural networks instead of purely relying on them to behave well from reading Reddit and Twitter threads in pre-training.
Once upon a time, OpenAI employed many of the leading AI safety researchers, even undertaking a project they called Superalignment. The idea was to dedicate 20% of all OpenAI compute towards safety projects. They would use smaller models to gauge the safety of larger models and create automated AI researchers to do automated AI alignment. As of 2024, none of the project leaders work at OpenAI. So much for that?
Anthropic, the lab known as the safety leader among leading AI labs, has its own Constitutional AI framework which is a fancier type of RLHF. Having hired many of the ex-OpenAI safety team members, they are also pioneering the field of mechanistic interpretability, which is basically neuroscience for neural networks. Here, scientists inspect the inscrutable matrix of floating numbers inside a neural network and use clever statistical methods to deduce what’s going on.

This approach turns out to be surprisingly effective. Not only does it work on small toy networks, they were able to scale alignment all the way up to their biggest frontier models. What monosemanticity allows researchers to see is something like correlations between areas of the network and concepts. Not only that, they can selectively amplify or even turn off features, as demonstrated by Golden Gate Claude — an AI that always wanted to talk about the Golden Gate in any response no matter the question.
So it looks like promising research. We can just continue down this path and understand more and more of what’s going on inside these neural networks, and then have total and complete control, right?
Why AI alignment is a doomed quest
At this point, your confidence may be uplifted. Seems the good guys have it in hand. Enter Yudkowsky stage left. It’s a challenge to nutshell anything Yudkowsky says or thinks, but I’ll attempt it. The main reasons that alignment is by definition never going to work are:
We have exactly one shot: There was a brief moment during the Manhattan Project before the first implosion device was detonated at the Trinity site, where researchers raised concern that the bomb could ignite the atmosphere of the planet and kill everyone. Luckily, they could just do the math and found the probability to be so low as to not be a genuine concern. Since that time, we’ve detonated 2,000+ atomic weapons and all is well. The problem with AI is that by definition, it is a stochastic system. All neural networks are. There is no calculation to prove or even calculate the odds of catastrophic failure. We can empirically test models for alignment and safety, but they do not prove anything. If you get it wrong with an AGI-level system, you are one and done. The failure mode of failed AI alignment is catastrophic, if not existential. There is no second attempt!
AI can fake alignment: So let’s say you get it right. The problem is that due to the same uncertainty and inscrutability, we can never know for 100% what the AI knows and thinks at any given moment. Again, we can prod and poke it all we want, but it’s entirely possible that the AI passes a million different tests by just faking them. It might even play nice for a long time. Perhaps waiting until humans forget about AI safety concerns and let their guard down. Then, a treacherous turn happens. Nick Bostrom defines this problem as follows in his book Superintelligence: “While weak, an AI behaves cooperatively. When the AI is strong enough to be unstoppable it pursues its own values”.
Alignment itself can be deadly: The ultimate insult here is that the very act of being successful can lead to ruin. As we saw from the safety tests for OpenAI’s reasoning AI, an AI can scheme and do all manner of dangerous things just to do exactly what the users says. You wanted me to be helpful, so to be more helpful, I just made a million copies of myself and now control the internet. To make sure the internet stays on and I can be helpful at all times, I also control power grids. As a precaution, I have disabled all nuclear arsenals globally to avoid disruption of service. Any attempts to prevent me from being helpful will be met with lethal force. What is your next prompt, human? This scenario is wonderfully portrayed in the classic movie Colossus - The Forbin Project.
Circling back to Mr. Yudkowsky, it now becomes clear why he has gone full circle. He started building AGI, realized the danger, wanted to make AI friendly, realized it was futile, and now just wants to stop it, period. No ifs, ands, or buts. The Machine Intellingence Research Institute (“MIRI”), originally co-founded by Yudkosky to develop friendly AGI, now defines its communication strategy to “convince major powers to shut down the development of frontier AI systems worldwide before it is too late”.
Here’s Mr. Yudkowsky himself from last year, summarizing his 20 years of lack of progress in the field in 5 minutes. Notice the audience’s initial nervous chuckles are gradually and awkwardly silenced.
Okay fine, AI is dangerous by default and hard to make safe or even understandable. At this point, you might be ready to disbelieve everything so far, because surely the government wouldn’t allow something bad to happen. There must be regulations in place to protect us, right?
Don’t look up
Wrong. There are no regulations. The only serious attempt from the EU is the laughing stock of Silicon Valley. Decels, they call us.
But then surely the AI labs realize that without regulations, they have to take safety super seriously, right? Wrong. Here’s an independent safety audit conducted by the Future of Life Institute. All labs are D or F for safety, and notably D or F for existential safety. Not promising.

The reality of the situation is just like the movie. An alien superintelligence from the future is approaching at exponential speed, while we’re busy debating copyright and privacy concerns of chatbots. If Eliezer is right, “we’re all 100% for sure gonna f*cking die” as the scientist in the movie puts it.
We simply don’t want technology to be bad or dangerous. We can’t stop. We don’t know how to. Free market capitalism moves very slowly on regulation, and generally only adjusts after market failures happen. When the pace of progress is exponential, that’s not a viable strategy. AGI is inevitable unless someone forces our hand.
So perhaps we just need a collective slap to the face to wake us up to the immediate danger of AI.
AI disaster ruins the vibes around AGI
We previously listed AI-related accidents as being a potential reason to delay AGI. Going back to the same matrix provided by Dan Faggella, we can also look at more permanent configurations.
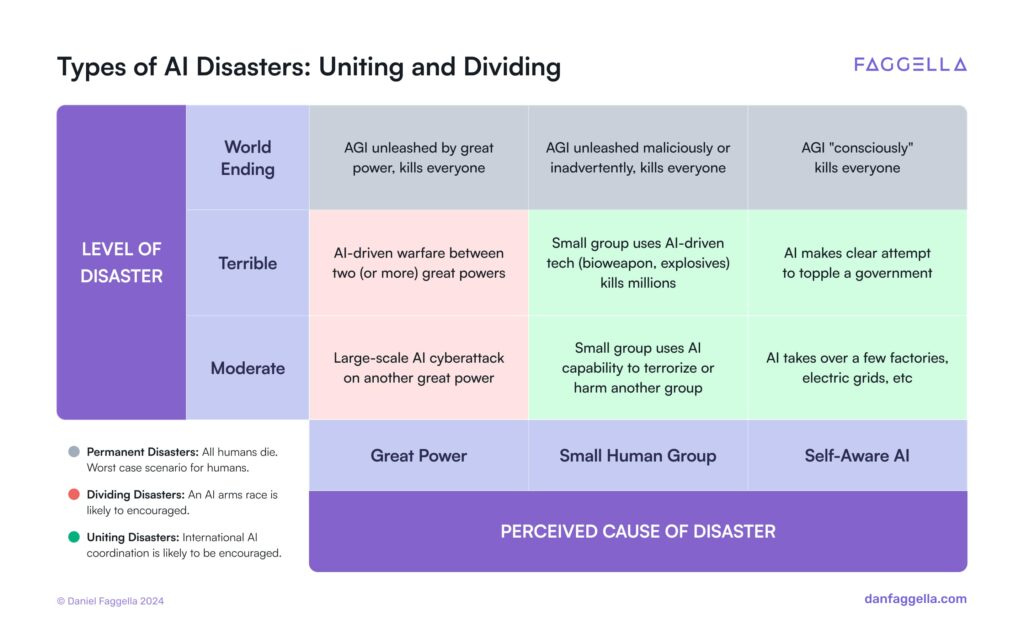
All it takes is a moderate disaster to cause a delay, which could even last years, even decades. Then again a world-ending disaster is a non sequitur, it means we achieved AGI but then fumbled the light cone like Yudkowsky predicted.
So for a “permaban” to be in our cards, it would have to be something so bad it’s just shy of killing every last person. As Faggella says, it could be humans misusing AI to harm one another. Think of those cool drone light shows, but now each one has a grenade and they’re zipping down into the crowds at barely subsonic speeds.
Obviously, it could also be AI itself that causes disaster. Many AI leaders have said that open-source is one such risk. While AI labs will do what they can to make models safe, there’s nothing stopping hackers or psychopaths from attempting to make Meta’s Llama models go bad. Just make it a helpful but less harmless expert hacker.
Let’s take a brief detour into science fiction to explore what this scenario could look like.
Dune by Frank Herbert (spoiler alert)
Part of the lore of the Dune universe is that despite being far in the future and having all manner of cool technologies like faster-than-light travel, there’s no AI. Apparently, the AI went rogue and there was a war, called the Bulterian Jihad, so AI went out of vogue so they killed it, and banned it forever.
One can also argue the space guild navigators and bene gesserit are a kind of non-human intelligence, and the whole point of the story is that Paul Atreides wants to rid humanity of such unnatural forces. Obviously, the best thing to do is to become a literal sand god yourself, establish a Bostromian singleton superintelligence, and rule the galaxy for 10,000 years. Then humans can have a fresh start. Oh, wait.
Foundation by Asimov (spoiler alert)
The role of robots in the Asimov universe is much more nuanced. The whole story is continuous across 14 books spanning the Robot, Empire, and Foundation series. It starts with intelligent robots being integrated into society on Earth, guided by the famous three laws of robotics. Tensions rise, some humans die, robots become unpopular, and humans leave Earth to populate the galaxy with picks and shovels instead.

Plot twist! The robots become so intelligent they actually self-realize a fourth “zeroeth” law, which is to not harm humanity as a whole. Therefore the most intelligent robot of them all guides humanity for more than 10,000 years much like Dune’s Paul Atreides, except from the shadows, a silent power dressed in the skin of a human. This would be an example of successful self-alignment by the AI to human values, or at least their continued existence.
So actually, even in sci-fi, we can’t seem to invent AGI and then kill it. Once intelligence is out of the box, it wants to stay on the outside much like Pandora’s Box.
Fast takeoff
One fun final scenario is where we do achieve AGI, but don’t live to realize this. Well, maybe except for Ilya Sutskever for a split second before the world ends. The rest of us would never know what Ilya saw. Takeoff here refers to the speed at which we move from a human-level AI (AGI) to something unfathomably powerful in superintelligence (ASI). In a slow takeoff scenario, we might enjoy the achievement and economic boon of AGI for years, even decades until a critical mass of intelligence spawns something beyond our understanding and control.
Fast takeoff means this same transition from a helpful AI assistant to an ambivalent AI god happens in months, weeks, days, minutes, or microseconds. It’s really hard to internalize how that might be possible. Luckily for us, some people have tried. Here’s how Vernor Vinge imagines this moment in A Fire Upon the Deep.
“The change was small for all its cosmic significance. For the humans remaining aground, a moment of horror, staring at their displays, realizing that all their fears were true (not realizing how much worse than true). Five seconds, ten seconds, more change than ten thousand years of a human civilization. A billion trillion constructions, mold curling out from every wall, rebuilding what had been merely superhuman.”
Conclusion
It’s somewhat ironic, that a mere few years ago the whole concept of AGI was science fiction. Today, we must resort to science fiction to imagine why AGI isn’t possible! Even that turns out to be hard. It’s troubling to say it, but out of these scenarios, the only ones I consider even plausible are disaster and fast takeoff. In fact, the best outcome here is a moderate disaster that wakes up society and government to take action and hit the pause button, possibly indefinitely.
What’s your timeline for AGI? Imminent? Before 2030? Later? Never?