
Road to AGI: Is it even possible?
Breaking down definitions for AGI and arguments for and against scaling

AGI, or Artificial General Intelligence, has finally entered the zeitgeist. It has been a scifi trope for decades, and a niche interest for futurists like Ray Kurzweil. The father of modern computing, Alan Turing, speculated on machine intelligence in his “Computing Machinery and Intelligence” paper from 1950. This is where we get the synonymous Turing Test from.
After several decades of repeating cycles of hype and winter, the surprising superhuman success of AlphaGO in 2016 sparked renewed mainstream interest in what’s possible with AI. Even that hype somewhat fizzled as these abilities were ultimately limited to a few board games. AI was successful only in it’s lesser form of Machine Learning, which had some commercial value in recommending which brand of toothbrush to buy on Amazon, and which Korean soap opera to watch next on Netflix.

This is why the unreasonable success of the transformer architecture and next-token prediction that powers ChatGPT has changed the conversation entirely. We’ve blown past the Turing Test so hard and fast that we never really even stopped to wonder. There are new and wondrous capabilities seemingly every other month now and the goalpost is moving with it.
So it seems to me, that now is the time to take stock and consider seriously how far we are from an AI that matches humans stroke-for-stroke. Not just in idle chat, but across all the things that we humans do that allows us to contribute to science, culture, and the economy.
Definitions of AGI
Before we can even have a discussion about Artificial General Intelligence (AGI), we really need to agree on what we mean by AGI. Let’s look at a few definitions from some of the main actors in AI.
Ben Goertzel: “AI systems that possess a reasonable degree of self-understanding and autonomous self-control, and have the ability to solve a variety of complex problems in a variety of contexts, and to learn to solve new problems that they didn't know about at the time of their creation.“
OpenAI: “Highly autonomous system that outperforms humans at most economically valuable work.”
Ilya Sutskever: “A system that can be taught to do anything a human can be taught to do.”
Geoff Hinton: “At least as good as humans at nearly all of the cognitive things that humans do.”
Elon Musk: “Smarter than the smartest human.”
It’s not hard to see that these are different goal posts. It seems plausible that we could reach OpenAI’s definition without ever touching Hinton’s version, let alone Elon’s vision of an AI Einstein. Personally, I find the way DeepMind’s classification into levels extremely helpful here.
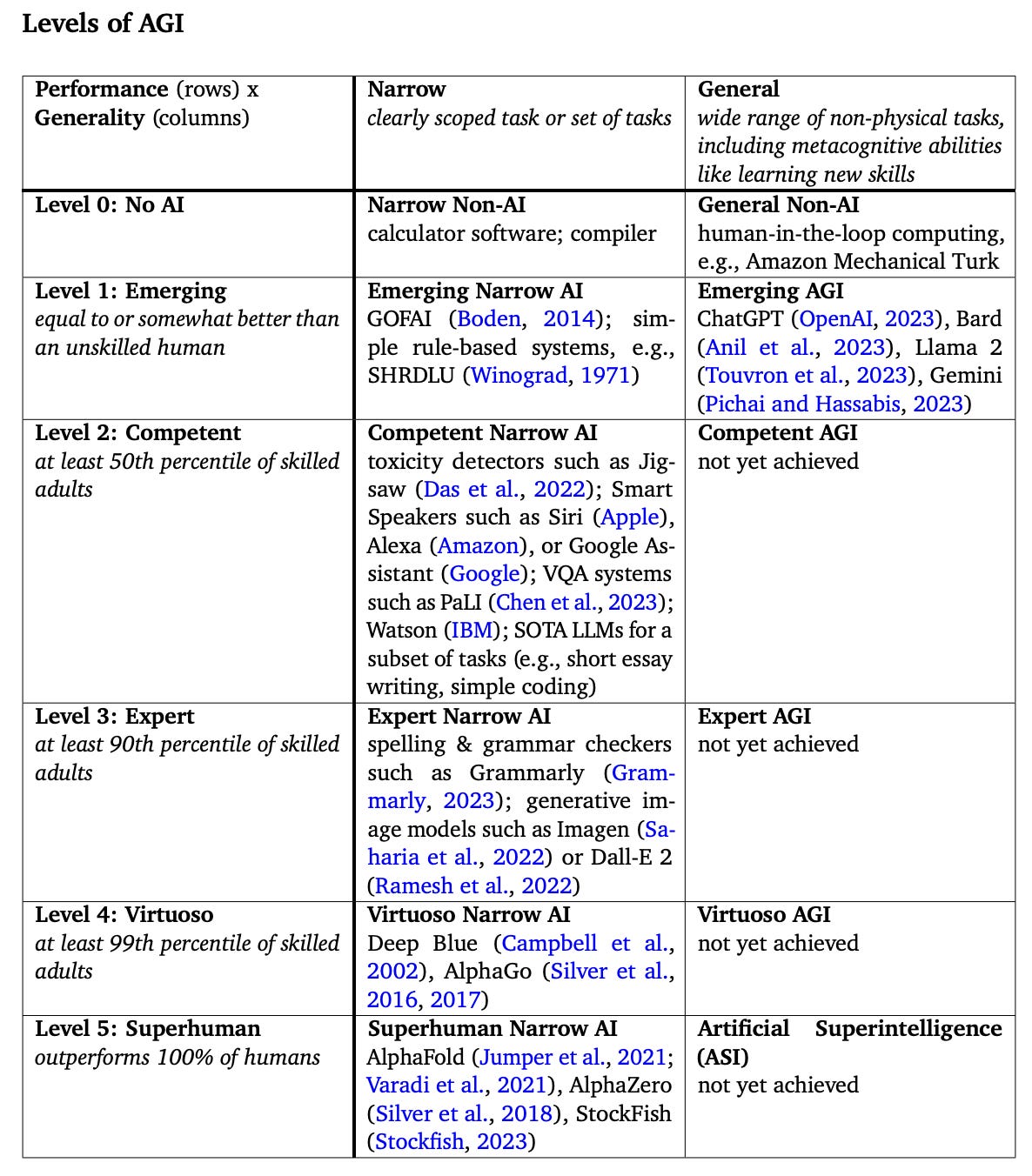
This gives us a clear framework to discuss AI progress, and also clearly separate Narrow from General AI. So if we’re now at Level 1 with ChatGPT, is it obvious that we can keep going up the levels at all?
What if there’s a ceiling to AI?
On one hand, you could easily imagine that over time AI just gets better and better, and that rate of change just gets faster. It’s an exponential fast takeoff, where AI just zooms by human ability.
If you think back to DeepMind’s previous claim to fame, in AlphaGO, we saw something like that happen. Their GO playing AI went from mediocre to superhuman in a shockingly short time span. The project started in 2014. They beat the European champion in 2015. In 2016, they beat the world’s best player Lee Sedol. For many experts, this was now the default expectation for any future AI modality. This is also when AI safety and existential risks from AI became a more serious concern among philosophers and academics.

Then again, just in the last two years, it seems ChatGPT got pretty good really fast, but progress since then has been impressive, but certainly not exponential like AlphaGO. Of course, we need to point out that AlphaGO was a “narrow” AI system focused on a singular task. Sure, they also made AlphaZero which could play several board games. But not write poetry or analyze stock markets. This is why AI systems like ChatGPT are considered truly “general”, whereby they can kind of do anything including play some board games.
Do we have evidence for one scenario over another as the paradigm going forward? I find this visualization by Toby Ord quite useful.

From the evidence, we in fact did not just breeze past the human range, as was hypothesized by some researchers. In theory, there isn’t anything special about human intelligence. Yes, it’s the highest form we’ve seen in the universe, but our limits are not the limits of physics and information theory. So what’s the snag? Why didn’t this chart end up looking like AlphaGO?
For obvious reasons, the debate currently centers around the present generation architecture, namely transformers and Large Language Models (LLMs). Instead of measuring ourselves against a singular benchmark like in board games, we measure LLMs against human performance across all relevant domains separately. What we can see is that we can make rapid progress on these benchmarks, but they start to clearly plateau at human level.

So far at least, we are training the models on human data. Perhaps it’s unsurprising, that when we set benchmarks such as tests for humans in various fields of study, we get human-level capabilities out. Some say we need synthetic data, others say we need to rethink LLMs completely. For example, the real breakthrough in AlphaGO’s success was not training on human data, so-called imitation learning, but with a radical new approach called self-play. In self-play, the AI learns by playing a copy of itself using reinforcement learning.
Current LLMs are based on imitation learning. While it sounds the obvious solution, the equivalent to self-play for transformers has proven much trickier. Still, several leading labs are known to be integrating reinforcement learning into their newest models including OpenAI’s “strawberry” family of models starting with o1.
If you follow AI experts on Twitter, there are two clear camps. One, championed by Gary Marcus, claims AI will basically never escape the Human plateau. Well, at least not LLMs. To be precise, even Gary thinks AI will eventually get there, but it could take decades or centuries, and that LLMs are a huge waste of time and resources. Same goes for Tesla Autopilot, by the way.
What if we can just keep scaling AI?
The other camp would call this pure “cope”. That attention really is all you need, and that the Chinchilla scaling laws are gospel. You add more data, and more compute, and humans are soon dust. Not literal dust, we hope.
This other camp includes some heavyweights like OpenAI co-founder Ilya Sutskever who famously told Anthropic CEO Dario Amodei that “the models just want to learn”. This was years before ChatGPT, and these guys haven’t gone back on their convictions one bit. Which also explains the billions and billions being poured into compute and data by the big labs. Their entire skin is in the game to prove they can do it.
Here’s a two-minute breakdown from Zuck, which also outlines the bull case for Nvidia stock pretty much indefinitely. He will keep buying GPUs until scaling stops working.
Jensen Huang’s GPU speed dial list includes Elon at xAI, Satya at Microsoft, Dario at Anthropic, and of course Sam at OpenAI. Interestingly though, Demis Hassabis at Google will design his own using AI.
What if we run out of data?
The more compute you have, the more data you need. This is what the Chinchilla paper from 2022 established: “For every doubling of model size the number of training tokens should also be doubled”.
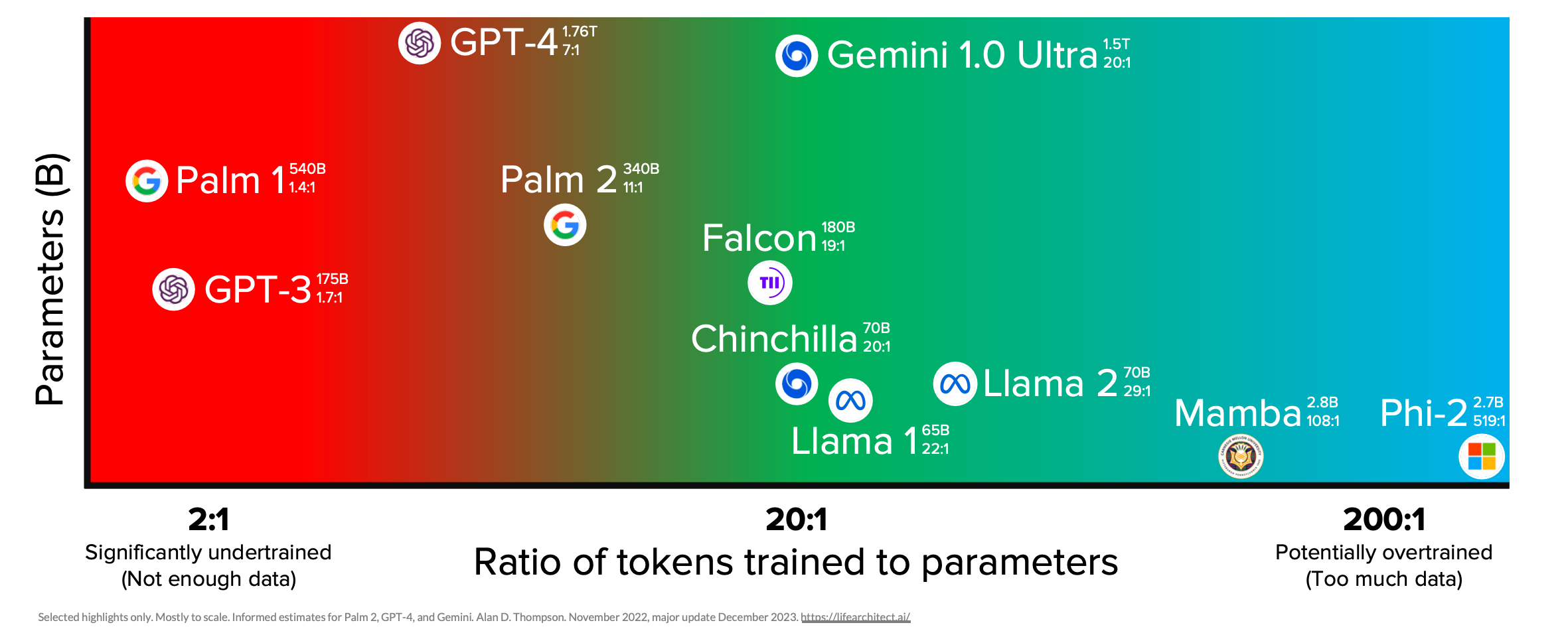
For small models that run on your devices, you might have too much data and need to filter it down to get the best model performance. However, at the frontier models, we are potentially running out of data.
To be precise, it’s data that would actually be useful. Datasets like Common Crawl and Fineweb are more or less all of the text on the internet. That comes out at something like 15 trillion tokens (think “word”) that you can train your LLM on. So if GPT-4 has 1.76 trillion parameters, at a 7:1 ratio of data to parameters, it’s still not using 100% of the tokens on the internet. But if you spend any time scrolling through these datasets, you’ll find they’re pretty random and poor in terms of quality. Perhaps quantity alone gave you a model like GPT-3, but beyond that, a lot of work has gone into curating datasets.
The more recent o1 model from OpenAI is an example where we have a very specific form of training data in the so-called Chain of Thought. Instead of training the AI on a bunch of problems and solutions, questions and answers, some part of the training data was formatted as question, process, answer. In some sense, this enables o1 to think more like a human might, and therefore solve problems that previous LLMs have struggled with.
Finally, we can use frontier models like o1 to also generate new synthetic data for the next generation of models. With each generation, we are probably using less and less of the raw data from the internet and more refined data that may have passed through many previous models that came before.
Other ways to scale AI
Besides more compute and more/better data, there are other ways in which AI progress might happen. After all, all those brilliant minds that make up AI labs are mostly focusing their energies on algorithmic improvements.

Consistently whenever OpenAI releases a new model, they also drop the prices. The famous Moore’s Law for transistors has held for decades and allows companies like Nvidia to double the power of their chips every two years. So far though, LLMs have seen more like an entire order of magnitude increase per year. That’s a lot faster. So every year your LLM is 10x bigger and also cheaper. Good deal.
This means that even if scaling data centers begin to slow down from shear logistical limits, then we can keep running bigger models on the same GPUs as our algorithms improve in their efficiency. Because all of this happened so fast, there are still a lot of places to find efficiency. Some are tuning new chips for training or inference. Others are exploring non-transformer solutions like Mamba.
Finally, there are the training regimes of the models themselves. Before ChatGPT came out, I remember seeing tweets about GPT-2 where you could only use it via API and the only thing it would do is complete sentences. The big jump to ChatGPT was instruction-tuning, which takes us from sentence completion to a chatbot modality. This was a big unlock in terms of the power and utility of LLMs.
Right now, we’re at a similar junction with the advent of agents. Unlike chatbots, agents may not even need to talk to us. They could independently perform tasks, using a variety of tools via APIs and code, and then report back results to humans. So far, this has been hard to pull off, but models like OpenAI’s o1 that are able to reason about more complex tasks are a step in that direction.
Others say that before we can reach AGI we need “embodied” AI, which usually implies robots. OpenAI had an early robotics program in-house but gave up before ChatGPT. Now though, they’ve invested in several robotics companies and there is a renewed push to marry the power of LLMs with the physical ability of robots. Tesla and Google have similar programs, too.
So it seems we have many ways to keep scaling toward AGI, and few are betting against it. So how close are we today?
How far are we now from AGI?
Going back to Google’s definitions, we might say the current frontier models of 2024 are Level 1 “Emerging” AGI. These systems are certainly better than unskilled humans in certain areas. They can write competent essays on topics that wouldn't embarrass you in front of high school teachers or even college professors.
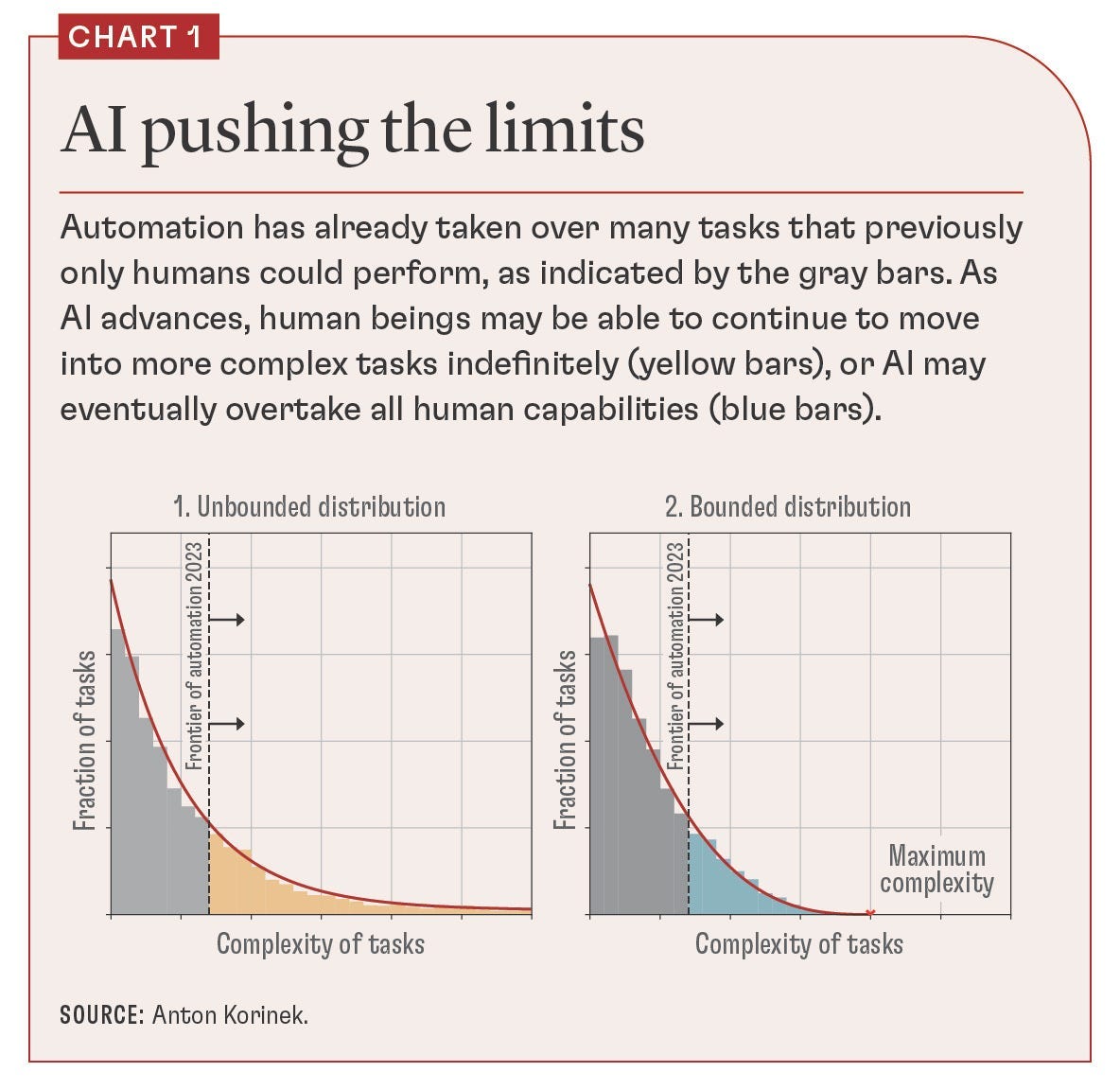
Reflecting on Korinek’s task complexity framework, it’s also clear that the boundary of how much complexity humans can handle is also dependent on the definition of “human”. In fact, we could imagine each level of AGI from Google’s definition matching a higher boundary of task complexity that humans can handle by their level of skill. A PhD level human can do a lot more than a high-school level human.
From this perspective, it’s not enough to have a Level 2 or Level 3 system if you perform well in a few tasks but not others. AGI is meant to be general, after all. This is still what separates humans as a category. We can be good at creativity, math, and reasoning all at once. This seems harder to produce in transformer models that are the basis of all current-generation LLMs. They might soon be superhuman coders, but still struggle with common sense puzzles a child could complete.
For example, it seems OpenAI’s latest o1 model has improved reasoning ability thanks to its novel inference time chain-of-thought mechanism, but on certain benchmarks, this approach actually performs worse than GPT-4.
Therefore it seems the jump to Level 2 is plausible within the same architecture, even if it requires a combination of tricks and scaling to get there. OpenAI has hinted its next-generation model, likely GPT-5, would be a PhD level assistant. On paper, this would seem equivalent to a Level 3 “Expert” AGI, but again this isn’t on a single domain. A human PhD can do a lot of things at an extremely high level, not just score well on science exams.
So for now, we are still trading between narrow specialized skills that are impressive, and a broad ability to perform tasks at a level and consistency that makes them economically valuable.
Next time, we’ll take a more in-depth look at what the potential timelines look like.