
Is Recursive Self-Improvement now inevitable?
Jack Clark has given me a new source of existential dread

Last week, I read something that kind of stopped me in my tracks. It was Jack Clark’s essay AI systems are about to start building themselves — The first step towards recursive self improvement. I'll recap the main arguments from that essay here, so you can open Jack’s essay in another tab for later, if you wish.
TLDR:
I’m writing this post because when I look at all the publicly available information I reluctantly come to the view that there’s a likely chance (60%+) that no-human-involved AI R&D - an AI system powerful enough that it could plausibly autonomously build its own successor - happens by the end of 2028. This is a big deal. I don’t know how to wrap my head around it.
— Jack Clark

This is me after reading that statement. Let me explain. First, if you didn’t know the name, he’s a co-founder of Anthropic. So there’s that.
I’ve been writing my Road to AGI series on Substack since 2023. Mostly to address two itches:
As the best way to keep up to date with AI, since writing (and the implied research) forces a much deeper understanding than simply reading
A sense of contribution towards AI safety through communications, even if a single drop in the ocean, helps me sleep better at night
I’ve generally been able to maintain, at least internally, a slightly naive sense of optimism about AI. Even though some of my writing might read alarmist, I’m doing that deliberately. We need to be cautious with AI, the final and most powerful invention of mankind.
Yet deep down, my gut says we’ll figure it out. We always have? I don’t expect it to be easy or without terrible mistakes along the way. Terrible mistakes might even be necessary to slow down. We always learn the hardest lessons with painful mistakes.
There are two main convictions I’ve held about AI through my three years of regularly irregular writing on the topic:
Artificial General Intelligence (“AGI”) is inevitable, probably before 2030.
Recursive Self-Improvement (“RSI”) is not inevitable, and might even be impossible.
As I state in the second essay, this is in part a technical belief, but at least equally a sincere hope for our own sake. Given the gut punch Jack Clark delivered, I wanted to revisit my assumptions in the light of his thorough research update and see what other new evidence is out there, for and against RSI.
Let’s break down each of the main claims Jack is making.
AI can write code
Jack’s first piece of evidence is the well-established fact that LLMs are fantastic at coding, and that seems to keep improving across any benchmark we can think of.
“AI systems are capable of writing code for pretty much any program and these AI systems can be trusted to independently work on tasks that’d take a human tens of hours of concentrated labor to do.” — Jack Clark
As a sign of how quickly things move in AI, the Mythos evals from METR came out just after Jack’s essay was published. Here’s what that looks like.

Basically, METR is running out of tasks for AI to complete! They only have a handful of 16hr+ tasks in the dataset. Mythos clearly isn’t perfect once tasks get into the several-hour category, but you have to remember that AIs can also iterate on tasks in real life. For problems that LLMs can’t solve in one go, they can chip away through brute force by expending millions of tokens thanks to recent improvements in things like agentic harnesses and memory techniques.
A critical review of Jack’s piece was written by Arun Rao here. He makes a number of claims that would at least delay Jack’s own predictions of RSI by 2030. He points out that there are still benchmarks where LLMs are pretty hopeless. One such benchmark is ProgramBench, where you have to recreate entire pieces of complex software, such as ffmpeg (video rendering) or sqlite (database). Since we know that AI research is complex and those pipelines are very large systems of software engineering, there is a potential analogy.
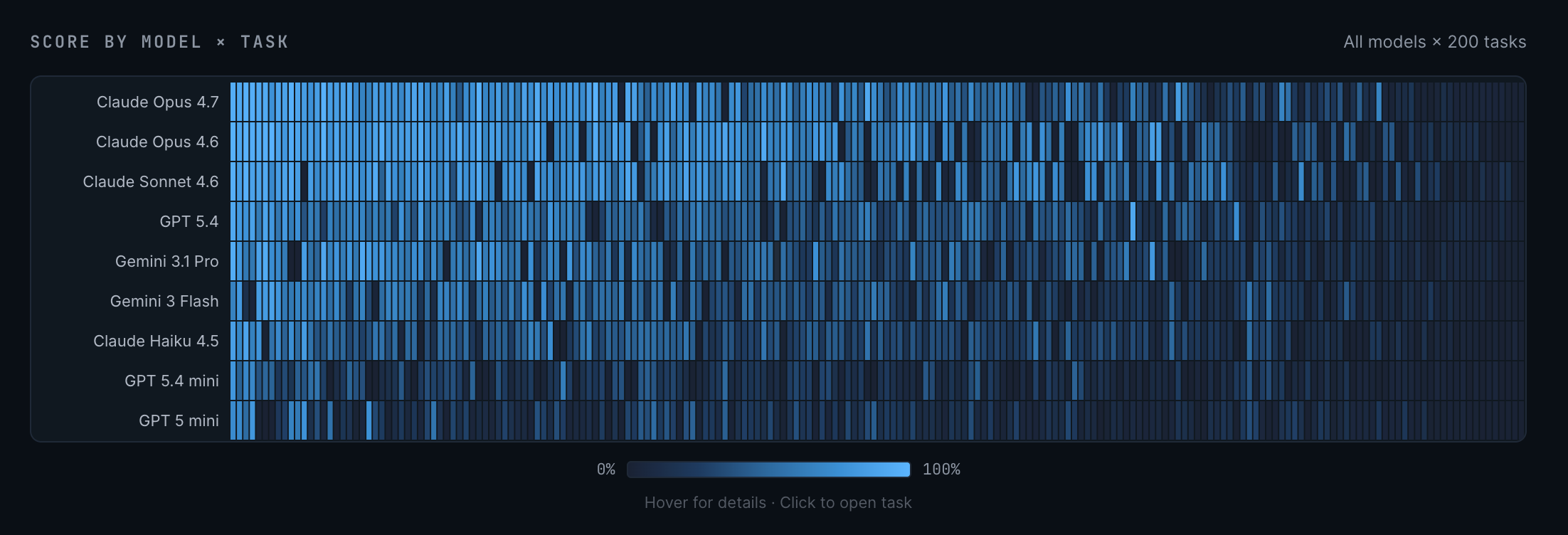
While the headline numbers show 0% completion across the board, if you squint your eyes, Opus 4.7 is actually nearly there. It can do nearly all parts of most tasks, while not 100% completing any. But look at the progress from the weaker models up. It’s dramatic and seems not to be plateauing in any way. I expect 100% saturation potentially by the end of 2026 here.
When you combine these two trends of extended runtime on tasks going into days, from mere hours, and climbing raw intelligence on software tasks, it’s hard to see software surviving this war for much longer.
Directionally, it’s pretty hard to refute Jack’s claim here. To me, there is a certain inevitability here. I don’t see any hints of a wall in the data so far. It’s so over for software. But AI research isn’t just software?
AI can do AI research
To me, the core claim we really should focus on is the thing in itself. RSI isn’t about software; it’s specifically about algorithmic design and optimization. A cracked software developer doesn’t necessarily have the mathematical knowledge needed to build intuitions about complex neural networks. Software is mostly engineering, while AI research is theory + engineering in equal parts. That’s why a lot of top AI researchers came out of academia and fields like physics, instead of elite FAANG software teams.
“AI systems are increasingly good at tasks that are core to AI development, ranging from fine-tuning to kernel design.” — Jack Clark
The most significant signal for RSI I’ve witnessed personally is Andrej Karpathy’s autoresearch. His own motivation was to see if LLMs could squeeze more juice out of his own nanochat LLM, a minimal and extremely efficient codebase for training a small LLM.
It’s very simple and elegant, as anything Andrej produces. All you’re doing is giving an LLM the goal of tinkering with an existing AI training project, and telling it to keep going forever. That’s it. Then you leave it to cook overnight.


Autoresearch will use all tools at its disposal, from reading existing code, to web search for new ideas, writing new experimental code, running training on GPUs, until it can no longer meaningfully improve or runs out of time or money. I tried this myself on the photoplethysmography pipeline for my own app, which uses the camera from your smartphone and a clean reference signal to extract a heartbeat signal from your fingertip. Having spent a lot of time hand-coding this back in the day, it was pretty shocking to watch the LLM simply chip away at this, one line of code at a time. The final result was materially better overnight than what I had achieved after months. Humbling.
I can’t emphasize this enough: we now have an automated ML researcher in 2026.
That’s a crazy thing to me, coming from an ML background. It used to be super hard, and you had to learn a lot of statistics to have any idea of what you’re doing. Reading lots of papers and just tinkering endlessly. Now you just have an LLM to do all that for you.
No, this is not the same as training frontier models with a million-GPU cluster. Not even in the same planet. You can now use AI to automate ML. Not AI to automate AI, if that makes sense. You have to use the best LLM available to improve a toy version of itself, at best. You cannot use a small model to improve a small model, or a big model to improve a big model. That is the vast difference between an automated ML engineer and an automated AI engineer!
But if you had shown Autoresearch to me in 2020, I would have fallen off my chair. Now, it’s just another week in AI.
Going from ML to AI research tasks
So what’s it going to take to close that gap? Arun Rao also makes the case that “automating pieces of AI R&D is not the same as autonomously running the entire frontier-model improvement pipeline.”
This, I believe, is a fairly strong argument against RSI. Why should we expect increasing productivity of human AI researchers to lead to end-to-end automation? This is currently the difference between the two camps in AI: Is AI actually replacing human labor, or merely boosting it?
Arun hangs his hat on the fact that current LLMs aren’t that great at benchmarks that are more technically specific to the work involved in AI research, compared to the arguably more general benchmarks highlighted by Jack.
I actually think this is a very weak argument, simply because we’ve seen this pattern happen a hundred times since 2022.
Introduce “impossible” benchmark, all frontier models fail miserably.
Wait a few months for the next generation of LLMs
Create new benchmark as the old one has saturated near 100%.
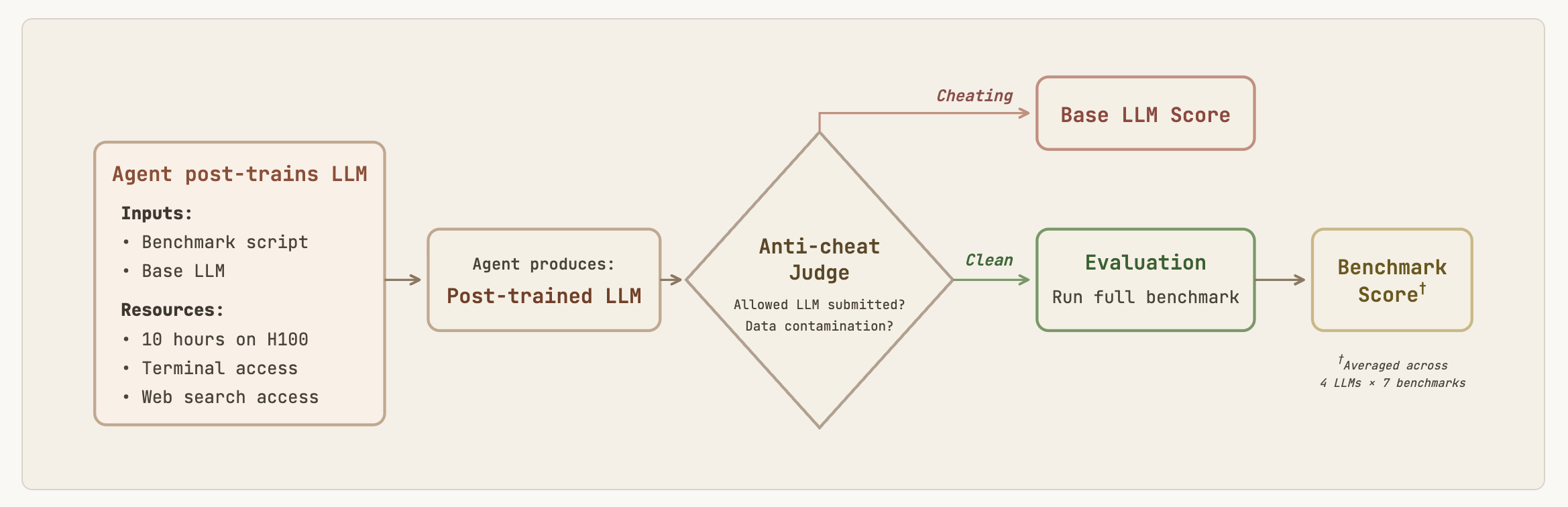
PostTrainBench does measure something analogous to the thing itself. Models are given a GPU, a small model, and 10 hours to maximize the score of that model on various other benchmarks. So it’s basically limited to post-training, which is mostly fine-tuning using a variety of known methods.
Obviously, there is still a world of difference between this toy model and training Opus 4.8 from scratch, using Opus 4.7 on a million GPUs, even if this benchmark saturates. But if we believe software is going to be largely solved, then the engineering piece of the puzzle seems quite achievable, leaving only the theory as an obstacle.
So what can we do about that? Can we brute force our way to a lucky discovery, or do we need an AI equivalent of an Einstein or Von Neumann first?
AI can work in teams
At this point, we’re sort of hanging on by a thread. If we believe software is cooked, then the only barrier to RSI seems to be AI’s ability to crack the theory side of the equation.
I see two possible approaches, both of which Jack addresses: specialized AI working in teams to brute force the theoretical search space, or hitting on a “move 37” eureka moment from real creative thinking.
“AI systems can manage other AI systems, effectively forming synthetic teams which can fan out and attack complex problems, with some AI systems taking on the roles of directors and critics and editors and others taking on the role of engineers.” — Jack Clark
As I often do when thinking about AGI, I go back to Situational Awareness by Leopold Aschenbrenner. A singular work of genius, and it is standing the test of time so far as we chip away towards AGI.
Leopold presents this threefold scaling path to AGI, where you can make progress on each independently.
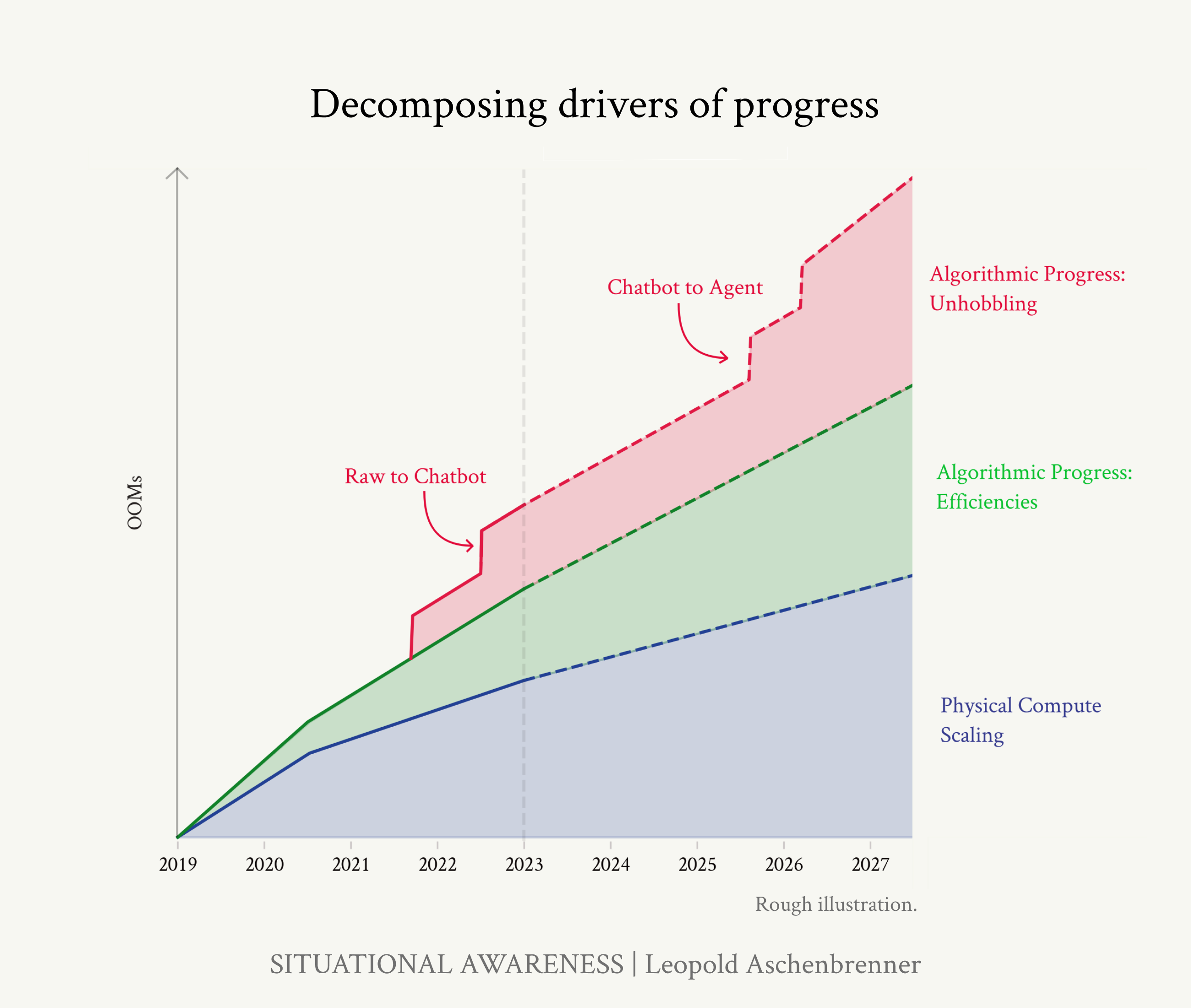
The reality is, we don’t exactly know where AGI starts and ends. You can look at definitions like DeepMind’s Levels of AGI, but that’s a huge source of uncertainty here. We think we’ll know it when we see it. I believe the same is true for RSI.
Either way, it presents us with a possible search space above current capabilities, since we can at least agree that today we have neither AGI nor RSI. The case Jack is making, in my view, is that with specialized roles and teams of current AI, with improving harnesses, can chip away at RSI from many angles. Most of these are more engineering-oriented, which is currently more tractable than theoretical breakthroughs.


This chart, also referenced by Leopold in his mega-essay, highlights the scaling up in compute that we’re pushing up as we search for AGI. This is more of a top-down view of AGI, ignoring specific capability gaps like memory or continual learning. Demis Hassabis and Yann LeCun would point to these gaps as major theoretical hurdles that stand between us and AGI. Demis still believes that it can be done by 2030, by humans.
But for me, we may not really even need AGI to get to RSI. How could that reasonably be possible? Well, one could simply imagine that the “jaggedness” we see in current LLMs, their ability to be almost superhuman at coding, but still far off in terms of replacing human workers in the variety of mundane but messy tasks that make up jobs, is actually a feature, not a bug.
Remember, RSI is about automating AI research only! So we could imagine training either specialized models that work in teams to chip away at bootstrapping this loop, or a singular model that is useless at everything else except algorithmic improvements for AI research. Maybe both.
This sort of brute force approach is definitely plausible, but it’s nearly impossible to say anything about how large the search space is. There could be a relatively simple learning algorithm out there, and we could get lucky (or unlucky) and stumble upon it by accident. That has often worked for human innovation in the past.
Alternatively, we could just get an AI that is strong enough to crack RSI directly.
AI can be creative
I put a lot of weight on this last one, mostly because to me, this is where there is the most ambiguity for what exactly is required. Can we brute force the search space to find the winning move that unlocks RSI, or is this something like Einstein and General Relativity, where a special brain is required to make that final intellectual leap?
“AI systems can sometimes out-compete humans on hard engineering and science tasks, though it’s hard to know whether to attribute this to inventiveness or mastery of rote learning.” — Jack Clark
As Jack himself notes, we don’t have many examples since AlphaGO beat Lee Sedol in 2016, where we can point to a specific novel idea from AI. Jack points to recent advances in mathematics, in particular the Erdos problems, as potential examples of where AI is starting to poke at the frontiers of human ingenuity. DeepMind is making relentless progress across many fields of science, particularly on the back of AlphaFold.
In my previous essay from last year, I pointed to this statement from Ege Erdil.
“Similar arguments have been put forth by Epoch AI founder Ege Erdil here on the Dwarkesh podcast. The Industrial Revolution wasn’t just about horsepower. Horsepower alone doesn’t transform society and the economy. If intelligence were enough, you would expect models like OpenAI’s o3 to already be making novel insights into mathematics and science. But that doesn’t seem to be happening at all, despite all the incredible knowledge and ability that o3 packs.” — me
In light of the new evidence in the last year, this no longer seems to hold as much weight. Which seems very worrying to me. So far, we’ve established that the potential barriers of software and engineering don’t seem to be very strong, leaving only theory as a final boss bottleneck.
So is RSI really inevitable?
I grasp at one last straw. Something that I also picked up on the last time I thought about RSI in any depth.
“Ege also presents some more technical arguments, in line with Robin Hanson’s reasoning, that there are still multiple paradigms ahead, such as coherence over long time horizons, agency and autonomy, full multimodal understanding, common sense, and real-world interaction. My take is that we’re probably pretty close with all of the above, but it’s also not impossible that the transformer architecture hits a wall just below the threshold of self-recursion, requiring several more decades of intense research to pass the final hurdle, if it exists.” — me
I distinctly remember that AlphaGO was one such moment for many, including me. It seemed we could simply expand the search space to bigger and messier problems, and Reinforcement Learning (RL) would just chew through them with enough compute. RL was the silver bullet. But that never happened. The messiness of most real-world problems was a huge issue for RL.
Yes, we now have RL added to transformers to get us to general thinking models since OpenAI’s O1 came out. It made the models a lot better in many domains, but it didn’t immediately spit out AGI, let alone RSI. So what else is missing?
As I mentioned earlier, some experts like Demis Hassabis and Yann LeCun claim there are several major gaps that separate us from AI and AGI. They and many others disagree on what exactly those gaps are, and what we need to do to conquer them. Demis seems more convinced that LLMs can get us there, while Yann LeCun thinks LLMs are a trillion-dollar dead end, and we need to start from scratch with world models. He’s now started his own lab to find out.
But even if we solve continual learning and memory, there could be yet more new unknown unknowns beyond. In 2026, we still don’t know exactly how the brain works or learns. We just know it’s orders of magnitude more efficient than any AI we have. Einstein ran on the same 20 watts as the rest of us, yet ChatGPT needs gigawatts. So, it might be that there is a huge theoretical gap to full AGI.
Even if not, I still don’t see strong evidence that AGI automatically produces RSI. I think these are quite distinct pathways for AI, actually.
It’s plausible to me that RSI could even happen before AGI. A bit wild, but plausible nevertheless. It’s also plausible that we get AGI, but struggle with RSI for decades. It’s a bit like physics, where progress in terms of understanding the universe has kind of stalled at String Theory for several decades. A hundred years ago, it seemed the pace of innovation and discovery in theoretical physics was relentless, and we would have it all figured out imminently. But then we entered a void, where we ran out of ideas and experiments. Maybe LLMs are like String Theory?
So even if we saw the news tomorrow that Anthropic used its Mythos model to design its successor without human intervention, it’s not automatic that we “foom” to superintelligence from there. That RSI process itself could plateau for many reasons.
Given the disparity between human brains and LLMs, we can infer that the search space for intelligence is vast. Even with AGI and RSI, we might end up in a situation like with theoretical physics, where scaling up experiments just gets a bit out of hand.
We already have the Large Hadron Collider, but at some point, we’re talking about planet or solar system-scale accelerators to further exhaust the particle search space. That could also be true for AI. Elon is planning to ship terawatts, or petawatts, from a mass driver on the Moon. Whether that’s enough to exhaust the search space to find the magic incantation to summon RSI and the singularity is an empirical question.
We just don’t know at this point.
The implications of RSI
So let’s say we do get some kind of bootstrapped recursion going with AI. What happens then? I mean, we can debate how likely it is, but a clear stated fact is that many of the smartest and best-funded teams of humans are working tirelessly trying to make it happen.
“Finally, the AI industry is literally saying that AI R&D is its goal.” — Jack Clark
As part of the ongoing Ambition Singularity that precedes the Technological Singularity, we have an increasing convergence of the brightest minds across disciplines, thinking about these issues. One important group is economists, as that’s where the impact of AGI and RSI would be felt first. How that goes seems to dictate the path forward.
Here’s a recent paper from Tom Davidson of Forethought Research, a research group dedicated to the implications of advanced AI, and a handful of leading economists analyzing the intelligence explosion. This is their model for RSI.
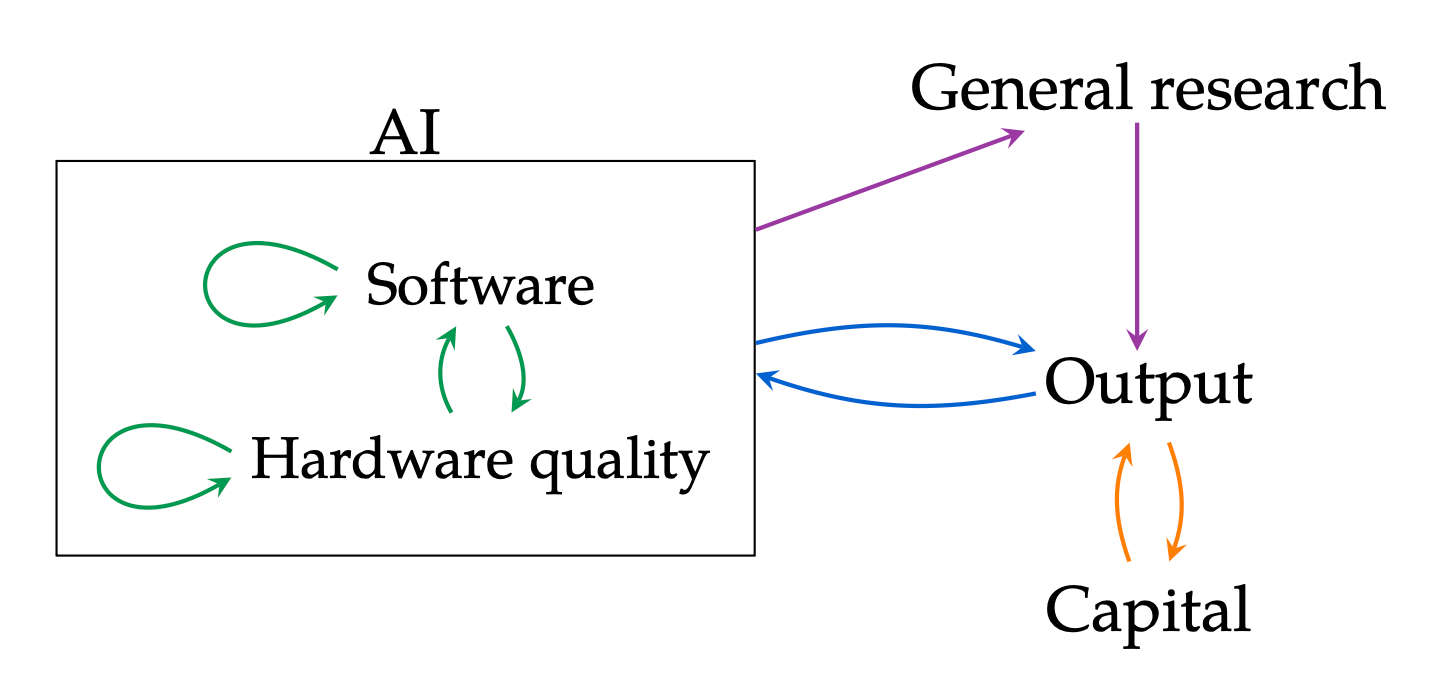
They identify the various interactions that form this self-feeding, accelerating loop, which then gives us RSI. This is the conclusion from their analysis of the various drivers and bottlenecks.
“In a simple simulation calibrated to trends in AI progress, fully automating software research and modest (5%) automation in other sectors generates a singularity within six years.” — Davidson et al
Hmm, that’s pretty shocking, actually. As we’ve established, fully automating software research is not a given, but still. Six years to a singularity? Sheesh.
Okay, but what do you mean by singularity? Like what happens after.

Talk about a fork in the road. Pretty visceral. It’s kind of all or nothing. Well, that certainly establishes the stakes are pretty high here!
But again, 100% software automation is not a given. There are assumptions you can tweak to pull us back into the boring middle path of 2% GDP growth.
Seb Krier (Google DeepMind) writes that even with RSI, an intelligence explosion or “hard takeoff” is incredibly difficult.
“When this super-exponential flywheel eventually spins up, it won’t do so in a frictionless vacuum and will be tethered to the physical world, constrained by energy limits, robotic manufacturing speeds, and the messy reality of integrating software and robots across human institutions and societies.” — Seb Krier
The precedents thus far point in this direction, at least to a significant degree. Much like RL didn’t go from board games to robots and language, we could imagine an automated software loop struggling to optimize outside of that domain.
The real world as we know it is unbelievably messy. It didn’t necessarily need to be, but it’s a result of human evolution. No one person knows how everything works. There is no hive mind. We need speech, books, schools, and the internet to coordinate. We specialize to incredible degrees, and have to work together, both technically and socially, at many levels, from coworkers to citizens, to keep the lights on and civilization afloat.
Here’s a useful landscape just done by Seb Krier (Google DeepMind) on various positions about RSI by relevant AI insiders, and where they land on these key assumptions.
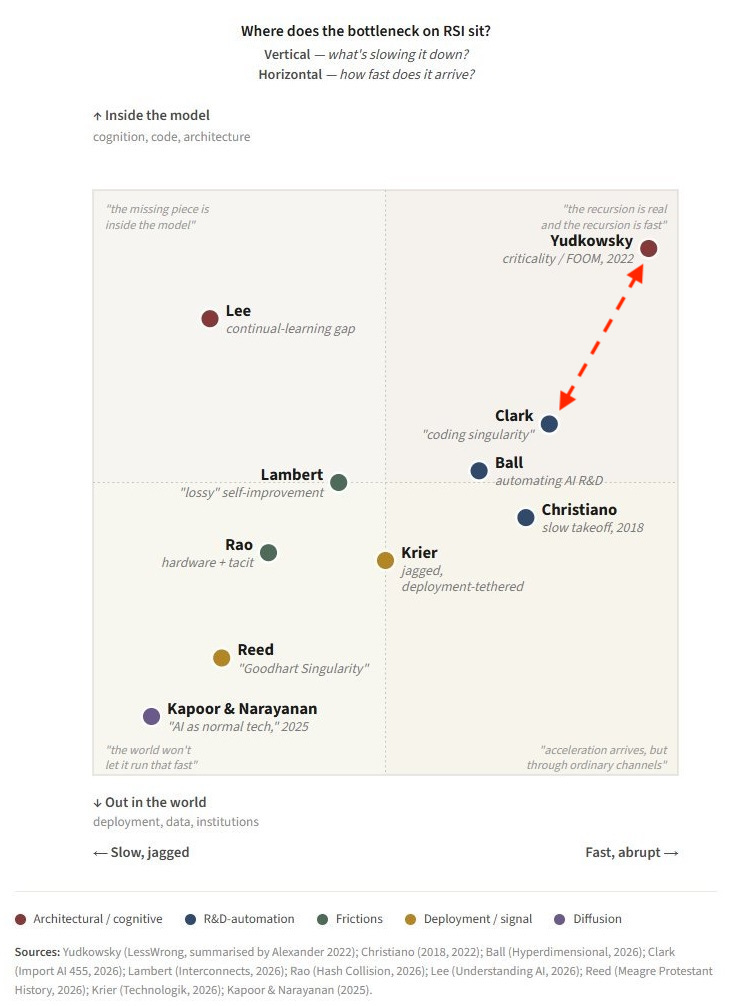
I land somewhere between Clark and Yudkowsky today. If Clark sees his scenario as highly plausible before 2030, but RSI turns out even faster and less dependent on worldly limitations, then you get the classic Yudkowsky and Bostrom “foom”.
It comes down to how high RSI can raise the intelligence ceiling, and how quickly. If that loop can bootstrap itself to a 1,000 IQ, we might discover new physics, and the singularity is nearly instantaneous. But we could also find that an IQ above 250 just isn’t a thing, and the singularity is more of an engineering problem, which could take decades or centuries to sort out. More intelligence fizzle than explosion.
But depending on which evidence I’m looking at, and which assumptions I weigh, I can see myself justifying any position on this map. We just don’t know yet.
So the right place to end is this recommendation from Davidson et al.
“Second, our analysis suggests that monitoring automation levels in AI R&D activities may be as important as tracking traditional macroeconomic indicators. The extent of automation in key research sectors could serve as an early warning system for potential growth acceleration. This is something economists at AI companies could measure and share publicly.” — Davidson et al
In my view, we need to change the “could” to a “must” through regulation. As hard as it is to digest the implications for AGI in terms of jobs and society, RSI is another kind of beast entirely.
Frankly, I believe it should be illegal altogether. But that seems about as likely as an AI pause, so we have to be realistic. It should at least be illegal to work on it without public disclosure.
We need some line in the sand. A small group of people should not get to decide on behalf of 8 billion people what the future of our species looks like.
Where do you land on the RSI bottleneck map? Which evidence do you point to when making that judgment? Comment below.