

What is the state of play with AI in early 2025? Are we in an S-curve of diminishing returns, or actually at the early stages of an exponential takeoff?
Well, the main method we use to gauge progress is “evals”, or evaluations. By definition, this is about choosing metrics by which to measure how well any given AI model performs. Remember, the models themselves are initially just trained to predict the next token. Whether those tokens are poetry, math, code, or a combination of everything are in part, albeit not entirely, determining the capabilities that come out at the end of training.
To compare model performance across time, researchers have come up with benchmarks that are some form of question and answer and therefore can be measured as a percentage from 0 to 100. Others measure preferences by comparing model outputs one-to-one, and this is usually measured via metrics such as win rate.
Currently, we’re in a kind of trench warfare between a handful of AI labs. For the longest time, OpenAI generally owned all the major benchmarks. Whenever other labs released new models, they had to cherry-pick some esoteric benchmark to show the public, and investors, that they were state-of-the-art (“SOTA”) in something.
Perhaps the one that still carries the biggest emotional weight is Chatbot Arena, where the public can blind-compare models simply by choosing which response they prefer. You could say this is the people’s champion, in that sense. OpenAI’s heavy investments into Reinforcement Learning from Human Feedback (“RLHF”) have been one key to its continued dominance in people’s preferences. Similarly, Claude from Anthropic was long considered to have the best personality, i.e., providing responses that people preferred.

Today’s picture is quite different. Claude isn’t even in the top 10, and after some back and forth, Grok-3 has narrowly kept the edge over GPT-4.5 at the top spot. Yet, preferences don’t say as much about raw capability as they do about being a wonderful chat companion. Claude is still the preferred LLM for most developers, for example.
This is why we have lots of benchmarks. But the problem is, we keep needing more.
Saturating the benchmarks
One of the main issues with benchmarks is that we keep running out of them. The original measure of raw intelligence has been Massive Multitask Language Understanding (“MMLU”), which is made up of multiple-choice questions across many scientific domains. Like most benchmarks, initially, this seemed a herculean task for Large Language Models. Over the past two years, models have gotten so good at MMLU that a more difficult version, MMLU Pro, was necessary. If models are all hitting close to 100%, you need harder questions to ask. Otherwise, you can’t demonstrate that the new model is in fact better, and worth the continued investment.

Worse still, we can’t always guarantee that models haven’t leaked some of this data into their training data. It’s not just the paper or source database, there are countless examples floating around in Reddit discussions and Twitter threads. All of that goes in the models, remember. This is called contamination and is often suspected when small models seem to perform well on benchmarks, but don’t pass the smell test. They just feel dumb.
Today, we have much harder exams for our AIs, and greater care is taken to shield them from contamination. We’ve moved on from high-school level questions to graduate level with GPQA and even further with competition maths in AIME. Currently, the pinnacle would be FrontierMath, which would probably challenge Terence Tao himself. These are not average human benchmarks. These are peak human benchmarks, pretty much the hardest questions our collective intelligence can produce.
Seems straightforward, what could go wrong?
The marketing game
Yet the same pattern keeps repeating. Benchmarks saturate toward 100%, so there’s not enough separation between the latest models. Investors won’t pay to beat the competition by 0.1%. Otherwise, it looks like the returns are diminishing, and scaling no longer makes sense. So, we keep coming up with new benchmarks, or at least new charts to dunk on the competition. Case in point: Grok-3.

This is actually a great example of the kind of marketing involved with these benchmarks. You need to show that your model is the best, even if it's only for a week before the next one comes out. Enough time to drop a few spicy tweets in your rival CEO’s timeline.
At first glance, it seems Grok-3 is the best at everything here. But then you notice the shaded area, which signifies extra compute allowed for Grok-3. Without it, the leading Grok-3 model, at an estimated cost of more than $300 million, would have fallen behind OpenAI and even Deepseek. That cannot happen, so instead you just present the data that suits your narrative.
OpenAI’s best model, the “full o3” powering their version of Deep Research, is also conveniently missing from the chart.
This leads us to how we measure reasoning models compared to pre-training models.
New benchmarks for reasoning models
If there is a singular storyline to mark AI progress in 2024, it would be the emergence of reasoning models. Many experts who were dismissive of LLMs said that they lack the ability to think or plan, often called “System 2” thinking. Well, now they do that, too.

This paradigm was ushered in with OpenAI’s “o” family of models, starting with 1 and then skipping 2 straight to 3. With test-time compute, we could see a new scaling law emerging. By allowing the AI to think for longer, we got better results for common benchmarks. But how do we actually measure pure reasoning beyond just questions and answers?
Back in 2019, noted researcher Francois Chollet was skeptical that LLMs could become AGI. He introduced the ARC-AGI benchmark, which resembles an IQ test. The questions are effectively visual puzzles that require different types of understanding about shape transformations that include simple physics. They’re not that hard for humans, generally. For each problem, you get three examples of the patterns and transformation steps, and then a fourth input pattern where you have to draw the output shape.

There is a public training set, but the test questions are privately held to avoid any contamination, i.e. cheating. Initially, LLMs scored basically zero. They simply could not do the kind of reasoning required to answer these questions. Given the naming of the benchmark, many considered this a true measure of AGI. Once we beat ARC, we have AGI.
Initially, the o1 launch from OpenAI seemed to actually confirm this theory. That even with increased reasoning capability, LLMs could not compete with heuristic-based narrow AI systems hand-crafted by experts. Mere months later, OpenAI’s o3 model basically ended the debate.

It’s clear that reasoning models will also saturate this benchmark. Not just beating the average human, but gradually bringing the price down. It’s just a matter of time.
But wait, I thought training had hit a wall by now.
Wall or no wall?
One of the rumors in 2024 was the idea that pre-training was hitting a wall. Even Ilya said it. That the only way forward was test-time compute, which is basically what reasoning models do.
We knew we would get to the bottom of this when we got access to the long overdue next generation of models, namely Grok-3 and GPT-4.5.
I wanted to compare base models as fairly as possible, on benchmarks where we have reliable results for several top models. This is what I found.

Granted, this is just a pretty narrow subset of benchmarks, as AIME is math and GPQA science. Currently, these are some of the most robust benchmarks we have. What we can clearly see, is that money does buy you a clear bump in performance. But it doesn’t come cheap. The ballpark is that you pay an order of magnitude in extra compute for each 10% bump at the frontier. Big boy stuff.
I don’t see a wall here. In fact, many are saying that Grok-3 is an example of brute-forcing pre-training. They had 100k of Nvidia’s finest GPUs hooked up, so they didn’t hang around and just let it rip. In reality, on the algorithmic side, they are probably still well behind leading labs. As Elon says, Grok-3 will keep getting better. They will keep adding hardware while improving the algorithms for pre and post-training.
We also have more data. Yes, we used up a lot of the internet, but video is mostly unexploited. Then you can just use robots to gather real-world data in embodied AI. Then there’s synthetic data. Maybe using reasoning models to create quality over quantity in training datasets.
The scaling will continue until morale improves.
We should also remember, that in terms of user preferences, the most expensive models ever created are sharing the first spot. Is that worth spending billions on? Probably yes, actually.
But why isn’t everyone using Grok then?
Are we really even measuring real-world performance?
There are a lot of nuances across all these benchmarks, but at the end of the day, you do have to ask how any of this translates into economically valuable tasks. Thanks to Anthropic’s investments into the personality of Claude, many still prefer it over models that seem to beat it in pretty much every benchmark.
This was particularly prominent in the reaction to GPT-4.5. Many critics were quick to declare “it’s so over” for OpenAI, as it wasn’t crushing the benchmarks as much as it was eking out marginal gains at tremendous cost.
In fact, when you look at code editing performance in the Aider Polyglot benchmark, it’s not even that good, and just as expensive as one of OpenAI’s biggest reasoning models! The value for money seems way off. DeepSeek V3 does a better job for 34 cents than GPT-4.5 at a whopping 183 dollars. That’s basically two orders of magnitude. What is the point of this expensive new model?!

Sam Altman had an interesting counter.
“this isn’t a reasoning model and won’t crush benchmarks. it’s a different kind of intelligence and there’s a magic to it i haven’t felt before.” — Sam Altman, OpenAI CEO
So what is it good for that we didn’t care about before? Here’s what OpenAI proposes.
Hallucination and factuality
One of the drawbacks of LLMs has been hallucination. They can give you convincing answers that are completely fabricated, or at least wildly confabulated. So OpenAI has shown that whatever makes GPT-4.5 special includes a clear improvement across actually saying true things.
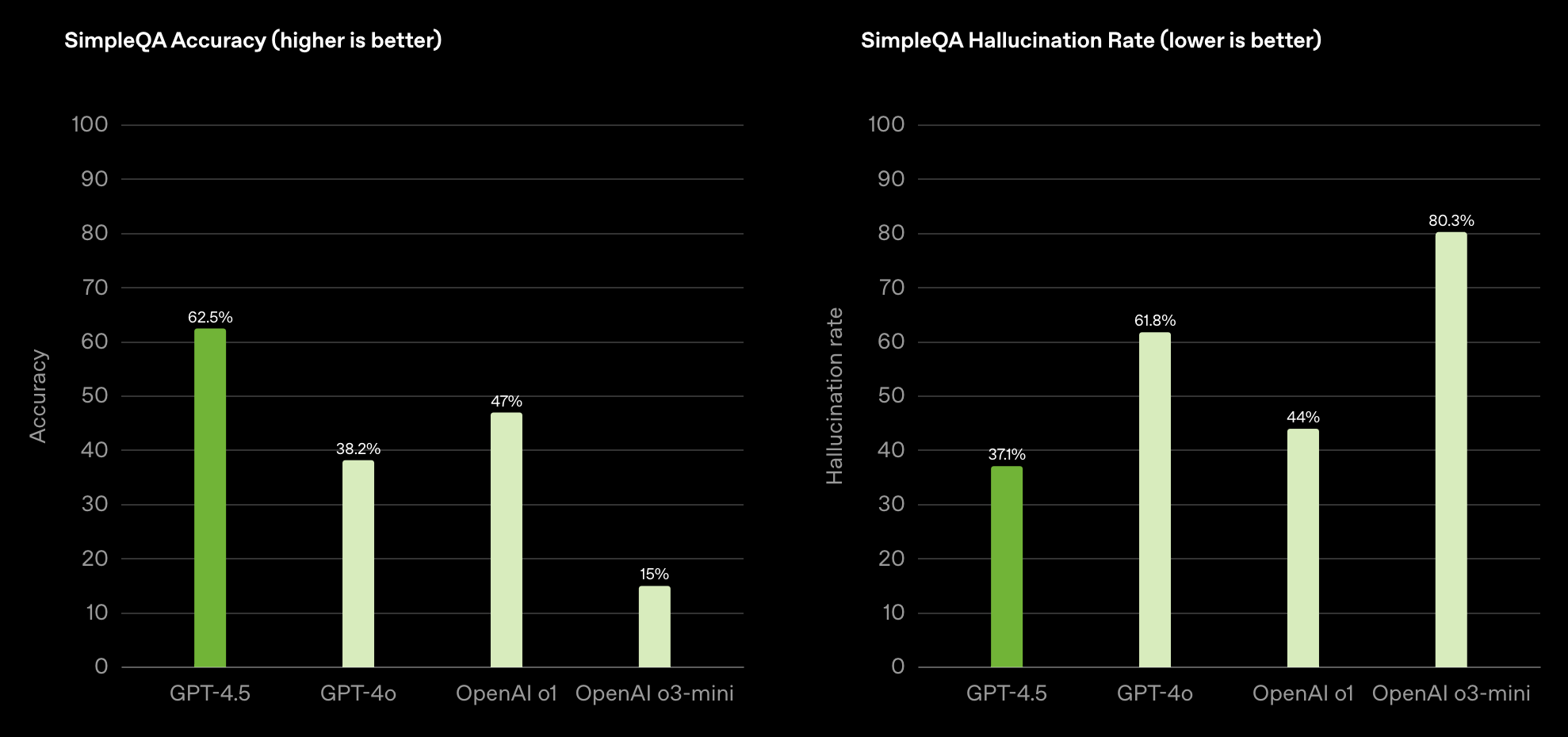
Okay, that’s promising. The biggest model beats prior models handily. What else?
IQ vs. EQ
Another thing people picked up on is the creative writing ability of GPT-4.5 compared to prior models. This model has jokes! Here’s an example, but you can find many more examples on Twitter.

This is the first time I read something genuinely funny from an AI, that actually made me chuckle. Obviously, you have to be familiar with Tyler Cowen’s flavor of intellectualism for this to hit home.
So where does all this leave us in the big picture? Is there such a thing as the perfect benchmark?
The final benchmark?
To end this bickering and confusion about benchmarks, Scale and the Center or AI Safety have designed the modestly titled “Humanity’s Last Exam”. The one benchmark to rule them all.
As we can see below, all major models at the time of publishing scored abysmally. So surely, if we beat this benchmark we have AGI?

I think we know how this story goes. Interestingly though, the people’s champion Claude 3.7 Sonnet currently tops the leaderboard at 8.93%.
So, is this how we get AGI?
Road to AGI
Besides the challenges of defining what we mean by AGI, I don’t see people shouting we have AGI after o3 beat ARC-AGI. It turned out to be just another benchmark. Meanwhile, we can’t even measure AI's impact on GDP yet. So something is still missing, but what is that special something?
What I would propose is to look at directly economically valuable tasks. Like coding. In terms of raw programming ability, it’s pretty clear that AI beats most human software developers on code challenges. Then again, you can’t really make that much money completing code challenges. Real-world programming is a mix of tasks and capabilities.
Beyond training better models, incredible progress has been made in “scaffolding” to make these AI models actually useful programmers. If we look at the progress from simple code completion in 2023 to integrated agentic systems like Devin and Claude Code, the writing does seem to be on the wall. The proportion of production code generated by AI vs. humans will soon tip over and never return.
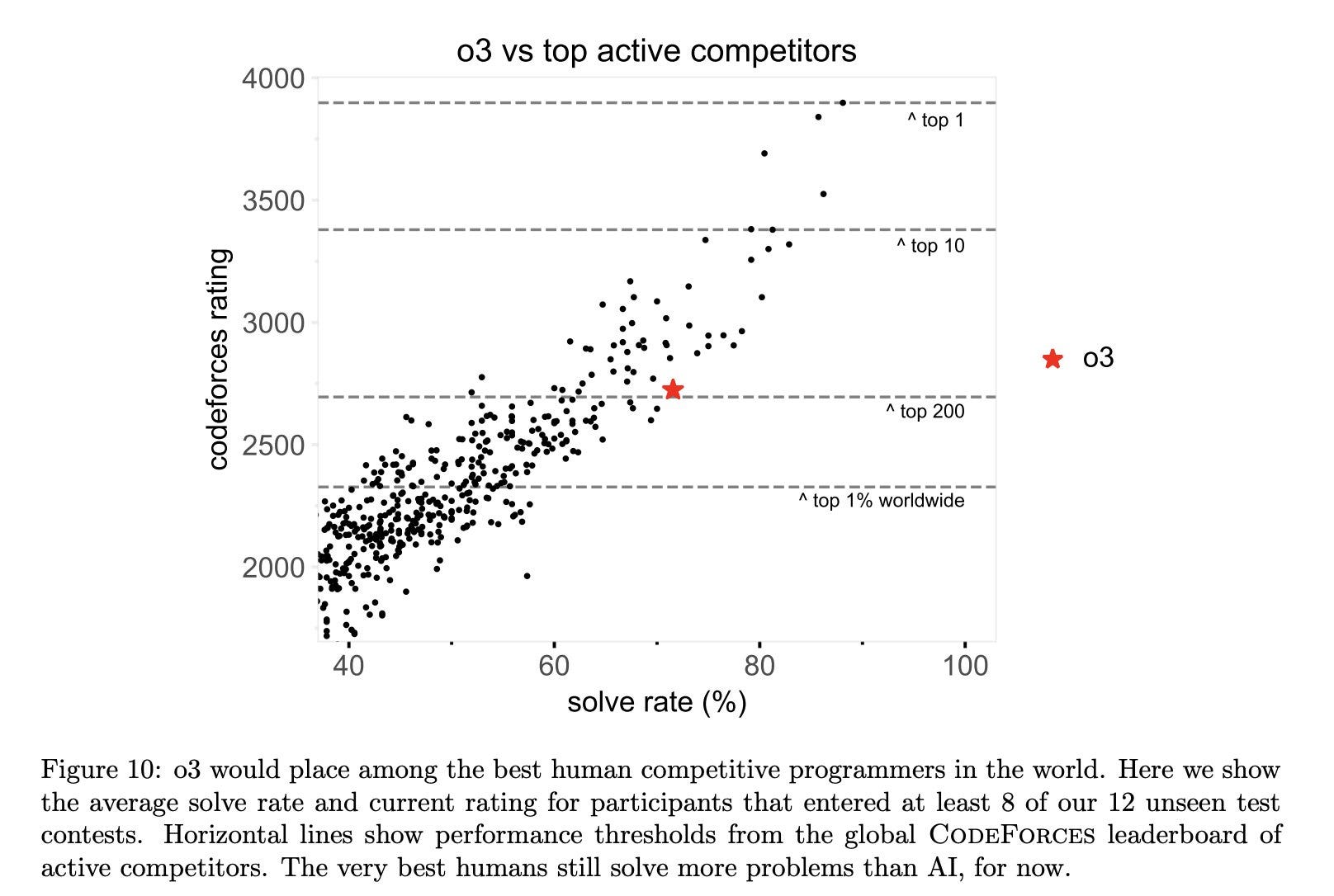
Another area where AI can make tremendous and easily measurable contributions is science. While AI already won two Nobel prizes, they were nominally given to humans. So can LLMs really come up with novel hypotheses and invent things?
If we start with scientific knowledge, that seems conclusively solved. The smartest AI on the planet as of today is OpenAI’s full o3 model, which you can only access via its Deep Research tool. Whether we ever see this particular model in a chatbot or API form is an open question. Perhaps it’s too expensive to be practical? Perhaps it’s too powerful to be safe.
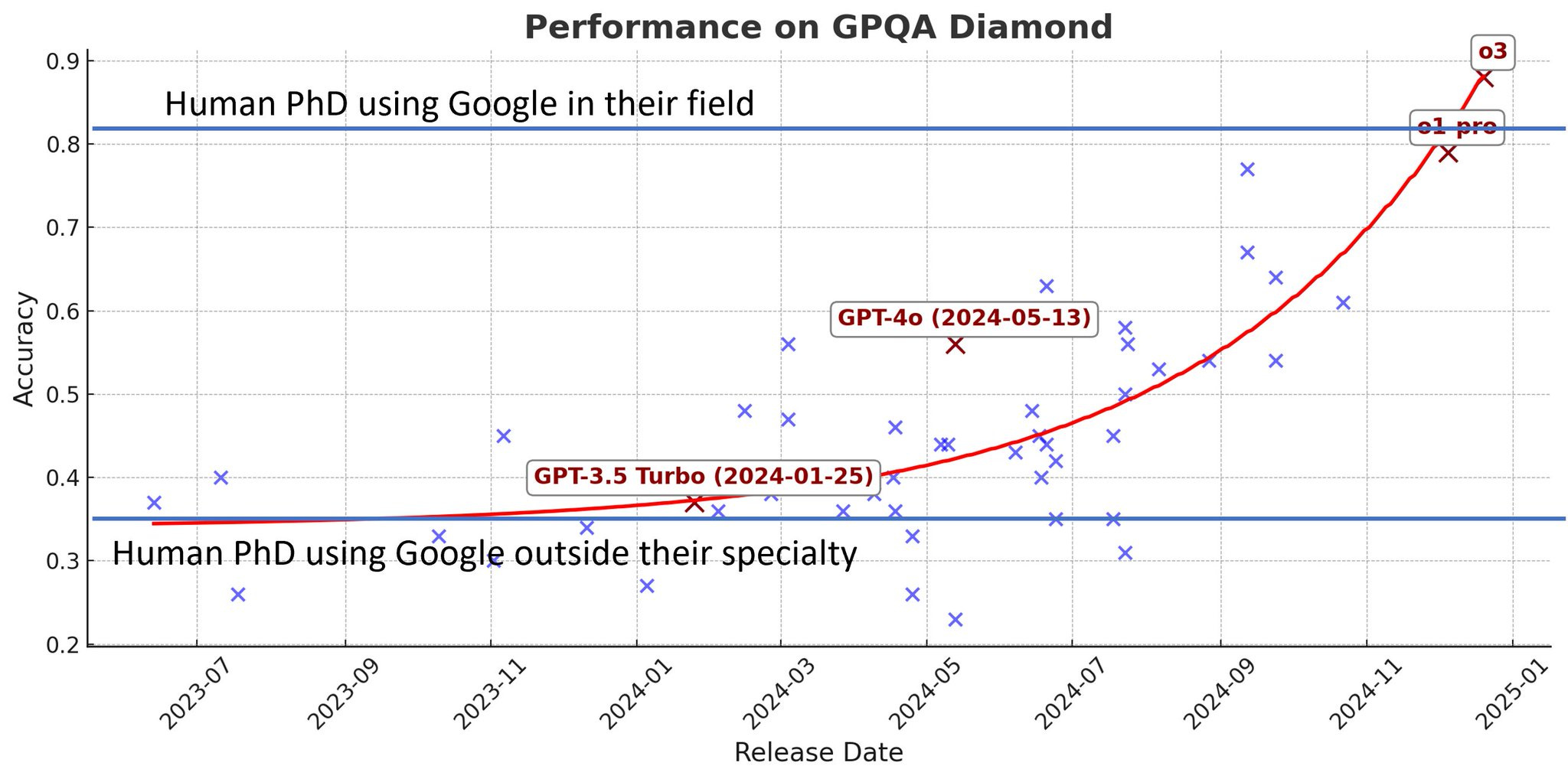
As crazy as that trajectory looks, it’s still one thing to answer questions that you could simply memorize and reason through, and a whole other thing to actually do new science. Not satisfied with just one Nobel prize, Demis Hassabis and the team at Deepmind are already back at it.
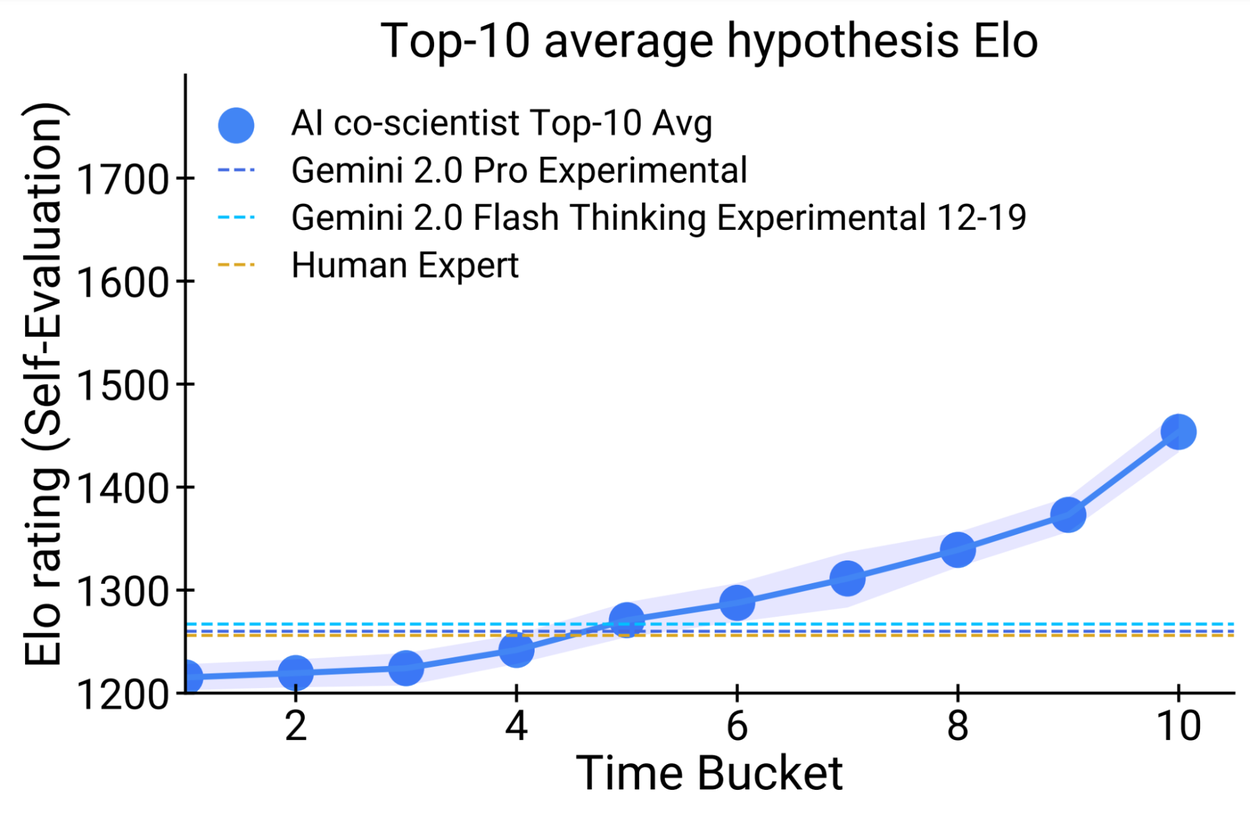
Now it’s worth remarking that an AI co-scientist is not a chatbot. This is a specialized model that could be considered narrow, not general AI. Much like how Deepmind became superhuman at board games like Go and Chess, they’ve now taken on the scientific method.
While I don’t expect the next Nobel prize winners list to be saturated by names of AI models, I find it hard to believe that frontier science will continue on pencil and paper. If we look at software development as a canary in the coal mine, then we should expect scientists to reshape their routines around AI to maximize output. Not just quantity, but also quality.
Progress in science is also progress in AI. I can only imagine the degree to which researchers at OpenAI are making use of o3, a model that only they have direct access to. One might imagine o4 to be at least partially thanks to o3.
When it comes to the broader economy, that gets solved with agents. What are agents? Here’s a refresher.
The Road to AGI is with Agents
So far in 2025, the biggest update in terms of AI progress came from METR (Model Evaluation & Threat Research). In their recent paper titled Measuring AI Ability to Complete Long Tasks, they give us a new exponential curve, yet another scaling law, and potentially even a new Moore’s Law for agentic AI. Here’s the chart that is turning heads among AI insiders.

Notice, very importantly, that this is not actually a straight line. Well, it is, but the y-axis is a logarithmic scale. Scaled normally, this plot would be very much exponential.
According to this data, we should expect a doubling along this trajectory every 7 months.
Just pause there for a moment, and think this through. During 2025, we will already see AI completing hours worth of human effort in one go. That means not only economically valuable tasks but probably entire jobs.
The other important fact is that the benchmark is set at a 50% success rate for tasks. The obvious question is what this would look like for higher accuracies. While 50% is already economically useful, there’s a material difference when a system can do a day’s worth of human tasks at 99% accuracy. How is that not AGI?

Lucky for us, someone had that very same idea and created this overlay. Extrapolating the differences between scores at different accuracy levels, we see two parallel sets of lines. One where we go past 2033 for 99% accuracy at 4-hour tasks, if we follow the trajectory from GPT-2 onwards. Yet if we choose the more recent aggressive trendline starting from 2024, we get to 2029. A four-year jump, and seemingly AGI before 2030!
“We think these results help resolve the apparent contradiction between superhuman performance on many benchmarks and the common empirical observations that models do not seem to be robustly helpful in automating parts of people’s day-to-day work”. — METR
This opens up the frankly rather terrifying possibility that this plot is actually going “superexponential”. Meaning the plot starts to look exponential even with a logarithmic y-axis.
In that scenario, we might expect the doubling rate itself to accelerate over time. If the starting point is 7 months, which is already very short, we could imagine being on the brink of dramatic acceleration.
Do you feel the AGI now?