
AGI Temperature Check #001
GPT-5, Scaling Laws, Missing AGI Capabilities, and Software jobs

There’s so much happening in AI that I find myself having writer’s block: I can’t pick what to write about, there’s just too much. Then, when you do pick a topic, it’s largely outdated information by the time it's published.
So, I’m trying a slightly different strategy, more of a summary of recent key ideas that I’ve been thinking about and talking about with other AI adjacent people.
I don’t intend to stray far from the Road to AGI thesis, so the contents will largely be around updated intuitions and evidence of AGI. Mentally, I’m thinking of this as a monthly update, but it might become more event-based than time-based in the long run.
AGI Timelines
Given the original motivation and the bulk of writing thus far in Road to AGI, focusing on AGI timelines, it feels natural that I should start there.
Launch of GPT-5 (-15℃)
The biggest overall update as of late has been the highly anticipated release of GPT-5. To understand the importance of this launch, you have to look back at everything that has happened since the launch of GPT-4.
Despite the fact that ChatGPT launched before GPT-4, it was this model that truly set the expectations for what LLMs could do for most of the world. It was not just the performance, but the price point and real-world usability in ChatGPT, but equally importantly, via the API. Most use-cases for businesses only really started working with GPT-4. GPT-3.5 could do some things, sometimes. Mostly writing-related. But GPT-4 could actually do things at a commercially viable level. Writing, coding, images, audio, and so on.
This level of impact is not easily reproduced in benchmarks. GPT-4 was seismic. This is easy to forget given how many models and products are coming out every month now.
Since GPT-4, the first reasoning models were also seismic: first O1 and then the widely adopted O3. We moved from mere chatbots into agents that could use tools like web search to deliver better answers, and take actions across systems for real-world business workflows.
So… was GPT-5 seismic? No. It’s just that simple. It’s more like a consolidation of the OpenAI model tree: GPT-4o with o3. Best of both: multi-modality and reasoning in one package at a reasonable price point. It’s a bigger leap in optimization than innovation. Do the benchmarks agree?

There is no doubt that GPT-5 is the best overall LLM in the world. Whether you measure by benchmarks or price, it’s right up there. But is it really that much better than, say, the prior reasoning king O3? I can’t tell, honestly. In fact, in some ways, GPT-5 behaves quite differently. I had gotten used to O3 as my daily driver, and I liked how keen it was to do web searches as external validation, even without asking explicitly. Then again, O3 had limitations on multi-modality compared to GPT-4o, so you had to switch models regularly depending on tasks. So GPT-5 is just your all-around workhorse AI.

So, where does this leave us in terms of timelines? I tend to agree here with Sriram, Senior White House Policy Advisor on Artificial Intelligence (former A16Z partner). If you look back at all the progress since GPT-4 in reasoning in particular, many expected GPT-5 to be AGI. Not a step toward AGI, but the thing in and of itself! It’s nothing like it, in fact. It’s a better thing, but ultimately a similar, familiar thing. There is no single distinguishing new capability unlocked.
More so, there were huge rumor mills between GPT-4 and GPT-5 in terms of things like “Q*” that supposedly unlocked intelligence and caused regular “vagueposting” by OpenAI researchers to spark rumors that “AGI has been achieved internally”. I see none of that now. There are no more rumors left. While speculative, this feels significant when you’ve been monitoring this as closely as I have, daily since 2023.
There is no doubt: GPT-5 was a major update against “AGI is imminent”. But, for reasons I’m about to explain, I don’t consider this strong evidence against AGI by 2030.
Scaling Laws (+0℃)
You can think of the so-called “scaling laws” as the underlying force of nature that has been powering AI progress since the birth of Deep Learning in 2012. These days, we have many scaling laws, and the term is used quite loosely to describe various trends with varying degrees of data to back up the hypothesis.
The original Chinchilla Scaling Laws paper from 2022 basically says that for any given level of compute, you need more tokens and a bigger model. Higher intelligence will appear. If we look at what’s happened since GPT-4, we can see a fork in the road, essentially.

We are scaling across two frontiers: the capability frontier and the cost frontier. Initially, this was just the difference between reasoning models vs. traditional transformers. Now, we may see further branching out. Especially, if you also consider open weight models, and even edge models meant to run offline on devices like smartphones. In some sense, between the very frontier of GPT-5 Pro and Gemini Deep Think, and something like Google’s Gemma, we see a fan shape.
We will continue to see more and more expensive models, pushing the capabilities benchmarks, and behind them a wake of optimization tradeoffs along some efficient frontier of intelligence per dollar. As of today, GPT-5 Pro is too expensive to be generally available to the public. You have to pay $200 per month for a mere handful of queries. So cost really matters. If GPT-5 Pro was what we got as GPT-5 in ChatGPT, opinions might be very different.

The latest scaling law that has drawn a lot of attention is that of AI agency, as measured in the human equivalent length of tasks AI systems can perform independently and accurately. If we extrapolate the current trajectory of AI agency, we would move into the territory of multiple days of accurate autonomy by 2030. Several days of AI autonomy is a seismic transformation from where we are today, from mere minutes to the low hours in software development tasks. Absent of any other data, that already seems quite strong evidence for AGI by 2030.
Is the continuity of that straight line on a log-plot guaranteed? Is AGI inevitable? Not at all! More research and innovation are needed.
Gaps to AGI
Think about all the breakthroughs that have made Moore’s Law continue unbroken for 60 years, and counting. Billions of dollars of annual investment in R&D. This hasn’t been about cost optimization. Each new generation of chips requires completely new technologies, requiring innovation at every level of the value chain, from chip design to foundries, to individual componentry making up the giant lithography machines. If you compare how transistors were made in 1965 to 2025, we have gone from 20 micrometers to 2 nanometers in scale. That’s a 10,000x difference.

As Ray Kurzweil has predicted for decades, the scaling of compute will continue, despite how hard it is. He hypothesized that when compute capacity reaches that of the human brain, AGI will magically pop into existence. I wouldn’t refute that based on GPT-5 as a singular datapoint. As long as we have more willing capital to push the frontier, we will continue to explore all available research avenues and expend more resources to find the next breakthrough. But one thing seems clear: more breakthroughs are needed.
Personally and long-term, I am bullish on environments and agentic interactions but I am bearish on reinforcement learning specifically. I think that reward functions are super sus, and I think humans don't use RL to learn (maybe they do for some motor tasks etc, but not intellectual problem solving tasks). Humans use different learning paradigms that are significantly more powerful and sample efficient and that haven't been properly invented and scaled yet, though early sketches and ideas exist (as just one example, the idea of "system prompt learning", moving the update to tokens/contexts not weights and optionally distilling to weights as a separate process a bit like sleep does). — Andrej Karpathy, Twitter
This tweet stopped me in my tracks. As one of the godfathers of the LLM era, Andrej has shown incredible taste and intuition about AI progress. He’s basically saying that scaling alone isn’t enough. New algorithms are needed.
The current AI paradigm we’re in is still based on scaling, but across multiple dimensions:
Compute (GPU)
Data (Synthetic)
Pre-training (LLM)
Post-training (Reinforcement Learning)
Since GPT-4 came out, most of the algorithmic improvement has come from introducing post-training, or test-time compute as a fourth scaling paradigm. By letting the models think first, they can solve harder problems. Given that we already scoured the internet for GPT-4 generation models, the way to scale data is now mostly synthetic (read: generated by AI). Especially Reinforcement Learning (RL) requires special datasets formatted to tasks, which are not readily available and must be painstakingly compiled by labs. Andrej’s comment was in reaction to the publication of an open RL dataset “gym”, where researchers can create and share environments to train better agents. Obviously, he’s skeptical of this direction as a path to AGI.
First, everyone said “attention is all you need”. Then it was test-time compute. But we don’t have AGI. Elon has the biggest GPU cluster in the world, by a wide margin, yet Grok-4 isn’t even that popular. It’s more of the same. More of the same ingredients aren’t currently unlocking the next frontier capabilities. So what’s missing?
The missing ingredients for AGI (-10℃)
Nobody knows! In past interviews, Yann Lecun, a notable LLM skeptic, has claimed we need a different architecture. Something he feels LLMs cannot incorporate is world models.
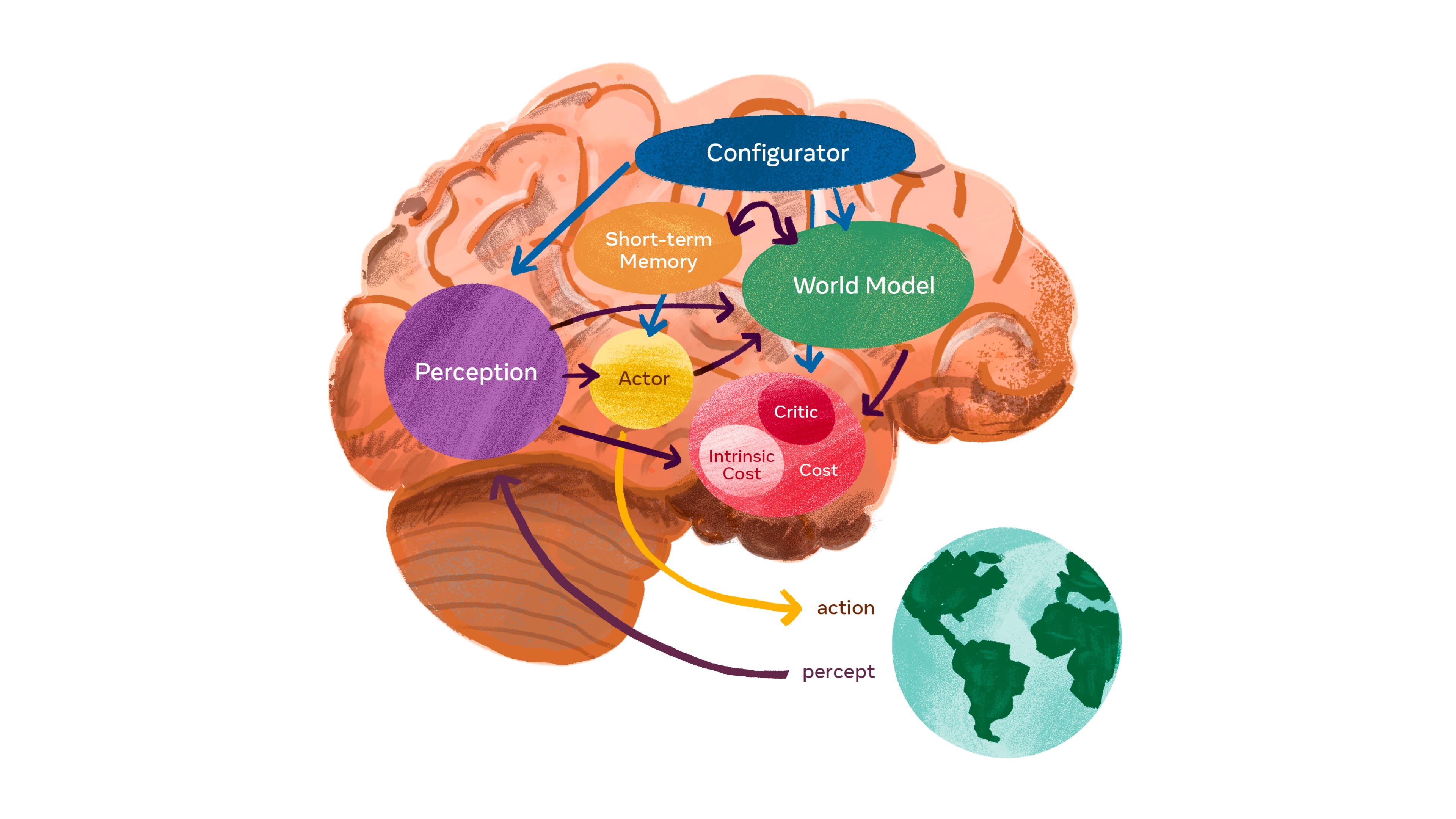
I’m less confident about that specifically, when you look at recent updates from Google, including Veo3 and “nano banana”. It seems LLMs can not just understand but generate realistic worlds, both in images, videos, and 3D simulations.
My personal intuitions from using current AIs are that we need at least two things, until they can truly act independently and move from tasks to human-level activity:
Memory consolidation — Yes, we need LLMs that can sleep. If you use something like coding models all day, they basically get alzheimers every 30 minutes or so, and you have to manually reset their memory. Yesterday, I got GPT-5 suddenly responding to me in Chinese! Despite longer context windows of up to a million tokens, the models just aren’t that efficient and smart about what to keep and what to disregard. For example, Claude Code automatically compacts, or compresses, the previous conversation once it reaches some internal limit of too much context. But humans can do this seamlessly over unlimited time horizons! We are far from human memory performance for now.
Online learning — Despite some evidence that the transformer architecture can use parts of its network to apply new knowledge within the context of a single query, the reality is that each new chat with ChatGPT is like rebooting. Yes, you can have memory from previous chats, but the model is exactly the same every time. Current LLMs are like Groundhog Day, or a clone that wakes up from the original state each time. One of the known keys to human learning is neuroplasticity, which we know also decreases with age. This is why children are better at learning new languages, for example. LLMs have very low neuroplasticity today because the architecture is not updating its weights regularly. Your GPT-5 is my GPT-5, and until OpenAI releases a new checkpoint, the model will not improve one iota.
Could these simply emerge from current architectures, as happened with so many other “impossible” tasks previously? Yes, anything is possible with AI. But it certainly wasn’t automatic. Perhaps, like with the Large Hadron Collider, we have to scale up much further to keep unlocking new capabilities and finding new particles. How long can we afford to search without finding our Higgs Boson equivalent? Time will tell.
Impact of AI
One of my long-held beliefs (long in AI terms, as in since 2023) is that even without AGI, we could already transform the world with AI. I mean, even before LLMs, DeepMind was innovating in domains as diverse as board games, biology, and weather predictions. We shouldn’t forget that Demis Hassabis’ Nobel Prize was for AlphaFold, not Gemini. So we shouldn’t get complacent that the amazing opportunities and risks of AI are only due when AGI arrives. We are already living in the age of AI. Diffusion just takes time.
Even if AGI is not around the corner, the appetite for compute and energy is going strong. You have to remember that while ChatGPT is popular among consumers, most jobs doing most processes in most companies haven’t even scratched the surface. We have 99% of the work ahead of us in terms of integrating AI into businesses, and that will drive incredible hunger for data centers and energy, even without AGI.
We ain’t seen nothin’, yet. If we look at the Industrial Revolution, at its peak, railroad spending during the Railroad Mania years in the UK was 73% of the national budget, altogether a cool 7 trillion dollars adjusted for inflation. Coincidentally, the very same number Sam Altman was asking for last year. There is much upside yet.

Meanwhile, the much-reported 95% of AI pilots fail was noise, in my opinion. Go look back at the news when the cloud was new, or when smartphones came out. Innovation is hard, reports the news… Instead, here is a real signal worth paying attention to.
Canaries in the coal mine (+5℃)
I wrote about how we should watch software developer employment closely back in September 2024. I called them the canaries in the coal mine. Well, lo and behold, here is a fresh paper from Stanford with the very same title, showing the first data to prove my hypothesis.

What we’re seeing here is the inverse pyramid replacement that The Intelligence Curse warned us about. Real-world jobs are not going to be replaced by GPT-5 Pro, because most jobs are not made up of solving PhD-level math problems. Instead, it’s agentic workflows using cost-optimal LLMs that are the risk, and the replacement starts from the bottom up.
I started my own career in software testing. Basically, manually testing software, writing test cases, running tests, replicating bugs, updating bug reports, etc.. The reason you would put juniors in this kind of role is that the risk of breaking something is much lower. You’re not writing new code for production. So you can learn the ropes before you can create any real damage.
It’s no surprise to me that we are seeing this split in economic outcomes. There is, in fact, more demand for senior developers who can efficiently leverage AI to increase productivity. I’m amazed at how much I can do solo now, just with AI. This has to do with the human’s ability to interpret and evaluate the AI output. If you’re junior, you might be easily fooled by the AI’s sycophantic tendencies of “You’re absolutely right!” when in fact, you’re going down a dead end.
Summary: AGI Temperature -20℃
Overall, the past few months have been a major AGI cooling signal for me. A welcome respite from the relentless hype we’ve seen in the past three years.
The rumors around algorithmic breakthroughs have died down beyond GPT-5. Something more is needed for AGI, but the specific speculation about new architectures has died down. While the scaling laws are intact, AGI does not seem imminent.
Yet I’m no Gary Marcus, and I don’t foresee any “AI winter”, either. I would, however, keep an eye out for the developing story around the job impact of AI. Things can heat up significantly well before AGI.